关注公众号不迷路:DumpStack
扫码加关注

目录
- 一、基础概念
- 二、几个重要的全局变量
- 三、ARM64解析设备树
- 3.1 arm64设备树信息
- 3.2 几个辅助的全局变量
- 3.3 parse_dt_topology - 从设备树中解析出cpu的算力
- 3.4 parse_cluster - 解析设备树中的cluster信息
- 3.5 parse_core - 解析设备树中的core信息
- 3.6 get_cpu_for_node - 解析capacity-dmips-mhz属性
- 3.7 topology_parse_cpu_capacity - 解析capacity-dmips-mhz的值并赋给raw_capacity[]
- 3.8 topology_normalize_cpu_scale - 向最大核做归一化处理,得到的cpu算力赋值给cpu_scale全局变量
- 3.9 当policy结构中的成员发生变化时,向最高频做归一化
- 四、ARM32解析设备树
- 五、判断一个cpu的剩余算力是否满足一个task的需求
- 关注公众号不迷路:DumpStack
一、基础概念
1.1 dmips是什么
mips(Million Instructions executed Per Second):表示每秒执行了多少百万条指令,用于衡量cpu的处理能力
dmips: D是Dhrystone的缩写,Dhrystone是一种整数运算测试程序,dmips表示cpu在运行这种测试程序时的mips,即dmips表示每秒执行多少百万条整数运算指令,Linux中用该值表示cpu的算力
dmips-mhz: 表示cpu在1MHz的频率下,每秒钟可以执行多少dmips
1.2 归一化scale处理
1.2.1 为什么要进行归一化
数据归一化又叫"特征归一化"(Feature Scaling)或"标准化"
特征之间的单位不同,不能直接进行对比或操作。比如身高和体重,比如摄氏度和华氏度,比如房屋面积和房间数,一个特征的变化范围可能是[1000, 10000],另一个特征的变化范围可能是[-0.1,0.2]。在进行距离有关的计算时,单位的不同会导致计算结果的不同,尺度大的特征会起决定性作用,而尺度小的特征其作用可能会被忽略,为了消除特征间单位和尺度差异的影响,以对每维特征同等看待,需要对特征进行归一化。
原则:样本的所有特征,在特征空间中,对样本的距离产生的影响是同级的;
问题:特征数字化后,由于取值大小不同,造成特征空间中样本点的距离会被个别特征值所主导,而受其它特征的影响比较小;例如:特征1 = [1, 3, 2, 6, 5, 7, 9],特征2 = [1000, 3000, 5000, 2000, 4000, 8000, 3000],计算两个样本在特征空间的距离时,主要被特征2所决定;
办法:将所有的数据映射到同一个尺度中;
注意:归一化的数值,即使是原来的单位不同,也可以进行加减运算
1.2.2 归一化的方法
1.2.2.1 最值归一化(normalization)
思路:把所有数据映射到0~1之间;
公式:
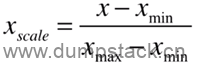
其中:
-
x为数据集中每一种特征的值;
-
将数据集中的每一种特征都做映射;
Linux中对算力,负载等特征的归一化,就是使用这个方法,只不过是归一化到1024
该方法多适用于分布有明显边界的情况;如考试成绩、人的身高、颜色的分布等,都有范围;而不是些没有范围约定,或者范围非常大的数据;
所谓"明显边界",就是同一特征的数据大小相差不大;不会出现大部分数据在0~200之间,有个别数据在100000左右;
1.2.2.2 Z-score(standardization)
思路:把所有数据归一到均值为0方差为1的分布中;
公式:
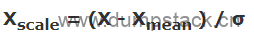
其中:
-
Xmean:特征的均值(均值就是平均值);
-
σ:每组特征值的标准差;
-
X:每一个特征值;
-
Xscale:归一化后的特征值;
该方法适用于数据分布没有明显的边界,即可能存在极端的数据值,归一化后,数据集中的每一种特征的均值为0,方差为1;
优点:相对于上面的最值归一化,即使原数据集中有极端值,归一化有的数据集,依然满足均值为0方差为1,不会形成一个有偏的数据;
二、几个重要的全局变量
算力计算步骤:
从设备树中读取dmips_mhz
获取cpu的最高频率,计算这个cpu的最高算力,dmips = dmips_mhz * policy->cpuinfo.max_freq
向最大核的最高频做归一化:cpu_scale = (dmips * 1024) / dmips[MAX]

2.1 raw_capacity[] - percpu变量,即设备树中的capacity-dmips-mhz属性的值
raw_capacity[]记录1MHz下的频率下的dmips,也就是在设备树中记录的capacity-dmips-mhz属性的值,该值由芯片厂商经过测试得到。raw_capacity[]变量只在初始化的时候被设置,之后不会再改变
该变量仅在U:\linux-5.10.61\drivers\base\arch_topology.c中使用,别的模块不会使用
|
static u32 *raw_capacity; |
2.2 cpu_scale - cpu算力,固定值,已向最大核最高频做归一化处理
cpu的算力,percpu变量,记录这个cpu工作在物理最高频率时的算力,(这里的最高频是指cpu的物理最高频率,并没有考虑policy限频的影响),该算力是向最大核的最高频做1024归一化后的值
该变量会被其他模块使用,所有kernel还提供了一些接口供其他模块获取该变量
2.2.1 arch_scale_cpu_capacity - 获取cpu算力
这里获取到的cpu算力是向最大核的最高频的做了归一化后的值,最大核的最高频为1024,该值不受频率影响
arch_scale_cpu_capacity的实现有平台自定义,例如在arm/arm64中arch_scale_cpu_capacity实际就是topology_get_cpu_scale
|
arch/arm64/include/asm/topology.h:46:#define arch_scale_cpu_capacity arch/arm/include/asm/topology.h:34:#define arch_scale_cpu_capacity |
对于没有定义arch_scale_cpu_capacity的平台,使用下面的方法实现对CPU算力的计算
函数位置:kernel\sched\sched.h
|
#ifdef CONFIG_SMP #ifndef arch_scale_cpu_capacity static __always_inline unsigned long arch_scale_cpu_capacity( struct sched_domain *sd, int cpu) { if (sd && (sd->flags & SD_SHARE_CPUCAPACITY) && (sd->span_weight > 1)) return sd->smt_gain / sd->span_weight; //通过sd参数计算得到
return SCHED_CAPACITY_SCALE; //默认是1024 } #endif #else #ifndef arch_scale_cpu_capacity static __always_inline unsigned long arch_scale_cpu_capacity(void __always_unused *sd, int cpu) { return SCHED_CAPACITY_SCALE; //默认是1024 } #endif #endif |
其中SCHED_CAPACITY_SCALE的值为1024,实现如下
|
/* * Increase resolution of cpu_capacity calculations */ #define SCHED_CAPACITY_SHIFT SCHED_FIXEDPOINT_SHIFT #define SCHED_CAPACITY_SCALE (1L << SCHED_CAPACITY_SHIFT)
其中 #define SCHED_FIXEDPOINT_SHIFT 10 |
2.2.2 topology_get_cpu_scale - 获取指定cpu算力cpu_scale
函数位置:include/linux/arch_topology.h
|
static inline unsigned long topology_get_cpu_scale(struct sched_domain *sd, int cpu) { return per_cpu(cpu_scale, cpu); } |
2.2.3 topology_set_cpu_scale - 设置指定cpu算力cpu_scale
函数位置:include/linux/arch_topology.h
|
void topology_set_cpu_scale(unsigned int cpu, unsigned long capacity) { per_cpu(cpu_scale, cpu) = capacity; } |
2.3 freq_scale - percpu变量,变化值,cpu当前频率向这个cpu的最高频率,做1024归一化后的值
注意:这个值不是想最大核最高频做归一化,而是向自己的最高频率做归一化,(这里说的最高频是policy->cpuinfo.max_freq,这个值是不受限频的影响的),当cpu的频率发生变化时,这个cpu对应的freq_scale也会发生变化
该变量定义的地方如下:
U:\linux-5.10.61\drivers\base\arch_topology.c
|
DEFINE_PER_CPU(unsigned long, freq_scale) = SCHED_CAPACITY_SCALE; |
注意:freq_scale是相对于本cpu的最高频做归一化的值,并不是向最大核的最高频做归一化,计算方法如下,不受限频的影响
|
scale_freq = (cpu_curr_freq / policy->cpuinfo.max_freq) * 1024 |
2.3.1 对外提供的接口:获取
2.3.1.1 arch_scale_freq_capacity
在arm/arm64中,该函数实现如下
|
arch/arm64/include/asm/topology.h:43:#define arch_scale_freq_capacity topology_get_freq_scale arch/arm/include/asm/topology.h:31:#define arch_scale_freq_capacity topology_get_freq_scale |
在U:\linux-5.10.61\kernel\sched\sched.h中实现如下
|
#ifndef arch_scale_freq_capacity /** * arch_scale_freq_capacity - get the frequency scale factor of a given CPU. * @cpu: the CPU in question. * * Return: the frequency scale factor normalized against SCHED_CAPACITY_SCALE, i.e. * * f_curr * ------ * SCHED_CAPACITY_SCALE * f_max */ static __always_inline unsigned long arch_scale_freq_capacity(int cpu) { return SCHED_CAPACITY_SCALE; } #endif |
2.3.1.2 topology_get_freq_scale
文件位置:U:\linux-5.10.61\include\linux\arch_topology.h
|
static inline unsigned long topology_get_freq_scale(int cpu) { return per_cpu(freq_scale, cpu); } |
2.3.2 对外提供的接口:设置
2.3.2.1 arch_set_freq_scale
在arm/arm64中定义如下:
|
arch/arm64/include/asm/topology.h:29:#define arch_set_freq_scale topology_set_freq_scale arch/arm/include/asm/topology.h:13:#define arch_set_freq_scale topology_set_freq_scale |
在U:\linux-5.10.61\include\linux\cpufreq.h中定义如下
|
#ifndef arch_set_freq_scale static __always_inline void arch_set_freq_scale( const struct cpumask *cpus, unsigned long cur_freq, unsigned long max_freq) { } #endif |
2.3.2.2 topology_set_freq_scale
|
void topology_set_freq_scale( const struct cpumask *cpus, //一个policy中的所有cpu unsigned long cur_freq, //当前频率 unsigned long max_freq) //这个policy所能达到的最高频率 { //即policy->cpuinfo.max_freq,不受限频的影响 unsigned long scale; int i;
if (WARN_ON_ONCE(!cur_freq || !max_freq)) return;
/* * If the use of counters for FIE is enabled, just return as we don't * want to update the scale factor with information from CPUFREQ. * Instead the scale factor will be updated from arch_scale_freq_tick. */ if (arch_freq_counters_available(cpus)) return;
//1.执行归一化操作 scale = (cur_freq << SCHED_CAPACITY_SHIFT) / max_freq;
//2.设置这个policy中所有cpu的freq_scale // 因为调频是以policy为单位进行的,因此设置freq_scale也是以 // policy为单位的,传入的cpumask类型的变量为这个policy中的所 // 有cpu,下面对这个policy中的所有cpu的freq_scale进行设置 for_each_cpu(i, cpus) per_cpu(freq_scale, i) = scale; } |
2.3.3 设置时机
在每次调频后设置
2.3.2.3 cpufreq_driver_fast_switch
|
unsigned int cpufreq_driver_fast_switch(struct cpufreq_policy *policy, unsigned int target_freq) { unsigned int freq; int cpu;
target_freq = clamp_val(target_freq, policy->min, policy->max); freq = cpufreq_driver->fast_switch(policy, target_freq);
if (!freq) return 0;
//1.因为cpu的频率已经发生了变化,需要更新freq_scale // 从下面传入的参数也可以看出,freq_scale的值为cpu的当前频率 // 向这个cpu的最高频率,做1024归一化后的值 policy->cur = freq; arch_set_freq_scale(policy->related_cpus, freq, policy->cpuinfo.max_freq); cpufreq_stats_record_transition(policy, freq);
if (trace_cpu_frequency_enabled()) { for_each_cpu(cpu, policy->cpus) trace_cpu_frequency(freq, cpu); }
return freq; } |
2.3.2.3 cpufreq_freq_transition_end
|
void cpufreq_freq_transition_end( struct cpufreq_policy *policy, struct cpufreq_freqs *freqs, int transition_failed) { if (WARN_ON(!policy->transition_ongoing)) return;
cpufreq_notify_post_transition(policy, freqs, transition_failed);
arch_set_freq_scale(policy->related_cpus, policy->cur, policy->cpuinfo.max_freq);
policy->transition_ongoing = false; policy->transition_task = NULL;
wake_up(&policy->transition_wait); } |
2.4 cpu_capacity_orig和cpu_capacity - 最大算力和剩余算力
cpu_capacity_orig,表示cpu工作在物理最高频率时所能提供的最大算力值,不考虑被policy限频的影响,该值来源于设备树,并向最大核的最高频做归一化后的值,是一个固定值
cpu_capacity剩余算力,该值实际就是cpu_capacity_orig扣除dl,rt,irq所消耗的算力后的剩余算力的值,该值是变化值
2.4.1 对外提供的接口:获取
2.4.1.1 capacity_of - 剩余算力,扣除dl,rt,irq后的算力
实现位置:U:\linux-5.10.61\kernel\sched\fair.c
|
static inline unsigned long capacity_of(int cpu) { //获取该cpu的剩余算力,也就是原生算力减去dl,rt,irq后的算力 return cpu_rq(cpu)->cpu_capacity; } |
2.4.1.2 capacity_orig_of - cpu运行在最高频所能达到的最大算力
实现位置:U:\linux-5.10.61\kernel\sched\sched.h
cpu_capacity_orig,表示cpu工作在物理最高频率时所能提供的最大算力值,不考虑被policy限频的影响,该值来源于设备树,并向最大核的最高频做归一化后的值,是一个固定值
|
static unsigned long capacity_orig_of(int cpu) { //原生算力,从设备树中读取capacity-dmips-mhz, //然后乘以这个cpu能达到的最高频率,并向最大核的最高频做1024归一化后的值 return cpu_rq(cpu)->cpu_capacity_orig; } |
2.4.2 对外提供的接口:设置
2.4.2.1 update_cpu_capacity - 更新cpu_capacity和cpu_capacity_orig
文件位置:U:\linux-5.10.61\kernel\sched\fair.c
|
static void update_cpu_capacity(struct sched_domain *sd, int cpu) { //1.获取剩余算力 unsigned long capacity = scale_rt_capacity(cpu); struct sched_group *sdg = sd->groups;
//2.赋值最大算力 // 对于arm来说,arch_scale_cpu_capacity就是直接获取percpu变量cpu_scale的值 // 该值不受cpu的当前的实时频率的影响,由上面对init_cpu_capacity_callback的分析 // 可知,cpu_scale的值只和policy->cpuinfo.max_freq有关,而后者又是固定值,是不 // 会变化的,因此这里的cpu_capacity_orig值的含义就是:这个cpu运行在最高频率时, // 所能达到的最大的原始算力 cpu_rq(cpu)->cpu_capacity_orig = arch_scale_cpu_capacity(cpu);
if (!capacity) capacity = 1;
//3.赋值剩余算力 // cpu_capacity是由scale_rt_capacity计算的到的,实际就是cpu_capacity_orig // 减去rq上的rt和dl的util,并为irq预留出util后,做scale(减去irq util), // 最终得到的capacity,所以,这个cpu_capacity可以这样理解:当前cpu的剩余算力 cpu_rq(cpu)->cpu_capacity = capacity; trace_sched_cpu_capacity_tp(cpu_rq(cpu));
sdg->sgc->capacity = capacity; sdg->sgc->min_capacity = capacity; sdg->sgc->max_capacity = capacity; } |
2.4.2.2 scale_rt_capacity - 计算剩余算力
所谓剩余算力,就是这个cpu的最大算力减去irq/rt/dl任务所消耗的算力
为什么要减去irq,rt和dl呢?这里主要是为了得到留给cfs的还剩多少算力
为什么对irq的计算要用比例呢?这主要是为了确保,无论多繁忙,都要给irq预留一定的空间
|
static unsigned long scale_rt_capacity(int cpu) { struct rq *rq = cpu_rq(cpu);
//1.获取这个cpu的原生算力 unsigned long max = arch_scale_cpu_capacity(cpu); unsigned long used, free; unsigned long irq;
//2.获取这个cpu在中断中消耗的算力,也就是在中断中的util irq = cpu_util_irq(rq);
if (unlikely(irq >= max)) return 1;
/* * avg_rt.util_avg and avg_dl.util_avg track binary signals * (running and not running) with weights 0 and 1024 respectively. * avg_thermal.load_avg tracks thermal pressure and the weighted * average uses the actual delta max capacity(load). */ //3.获取这个cpu在rt和dl任务时消耗的算力,即util used = READ_ONCE(rq->avg_rt.util_avg); used += READ_ONCE(rq->avg_dl.util_avg); used += thermal_load_avg(rq);
if (unlikely(used >= max)) return 1;
//4.计算剩余算力 // 因为算力和负载都是经过归一化后的值,特征属性都被弱化掉了, // 可以认为单位是相同的,因此可以直接进行加减操作 free = max - used;
//5.个人认为,下面的计算是想为后面irq预留出一部分算力 return scale_irq_capacity(free, irq, max); } |
2.4.2.3 cpu_util_irq - 获取在irq中的负载
实现位置:U:\linux-5.10.61\kernel\sched\sched.h
|
#ifdef CONFIG_HAVE_SCHED_AVG_IRQ static inline unsigned long cpu_util_irq(struct rq *rq) { return rq->avg_irq.util_avg; } #else static inline unsigned long cpu_util_irq(struct rq *rq) { return 0; } #endif |
2.4.2.4 scale_irq_capacity - 为后面的irq预留一部分算力
首先需要搞明白下面三个参数的含义:
util:当前cpu算力,减去此前rt和dl消耗的算力,剩下的剩余算力
irq:在此之前irq所消耗的算力
max:当前cpu原生的最大算力
下面在计算剩余算力的时候,要给irq预留一部分算力,公式如下,其中max-irq/max表示预留irq后剩余算力的百分比,再乘以util,得到最终的剩余算力
|
max - irq U = ------------- * util max |
实现位置:U:\linux-5.10.61\kernel\sched\sched.h
|
#ifdef CONFIG_HAVE_SCHED_AVG_IRQ static inline unsigned long scale_irq_capacity( unsigned long util, //减去rt的dl后得到的剩余算力 unsigned long irq, //之前在中断中产生的负载,即中断消耗的算力 unsigned long max) //cpu能够提供的最大算力 { util *= (max - irq); util /= max;
return util;
} #else static inline unsigned long scale_irq_capacity( unsigned long util, unsigned long irq, unsigned long max) { return util; } #endif |
在schedutil_cpu_util函数调用scale_irq_capacity的时候,有下面的注释,可知:因为irq和steal-time的运行时间,在task clock中是统计不到的,因此需要为这些时间预留出时间
|
/* * There is still idle time; further improve the number by using the * irq metric. Because IRQ/steal time is hidden from the task clock we * need to scale the task numbers: * * 1 - irq * U' = irq + ------- * U * max */ |
三、ARM64解析设备树
解析工作主要分三步:
-
解析设备树中的capacity-dmips-mhz属性的值,并赋值给raw_capacity[]全局变量,此时是对应1MHz下的mips
-
向最大核的dmips-mhz做归一化,公式如下:
|
raw_capacity[cpu] cpu_scale[cpu] = ------------------------------ * 1024 MAX(raw_capacity[0..NR_CPUS]) |
-
当policy成员发生变化时,(对应通知CPUFREQ_POLICY_NOTIFIER,实际上我们只关注policy->cpuinfo.max_freq成员的变化),调用回调函数对cpu_scale向最大核的最高频做归一化
3.1 arm64设备树信息
文件位置:arch\arm64\boot\dts\hisilicon\hi3660.dtsi
|
cpus { #address-cells = <2>; #size-cells = <0>;
/* cpu-map中记录着每个cluster中包含的cpu核的信息 */ cpu-map { cluster0 { core0 { cpu = <&cpu0>; }; core1 { cpu = <&cpu1>; }; core2 { cpu = <&cpu2>; }; core3 { cpu = <&cpu3>; }; }; cluster1 { core0 { cpu = <&cpu4>; }; core1 { cpu = <&cpu5>; }; core2 { cpu = <&cpu6>; }; core3 { cpu = <&cpu7>; }; }; };
cpu0: cpu@0 { compatible = "arm,cortex-a53", "arm,armv8"; device_type = "cpu"; reg = <0x0 0x0>; enable-method = "psci"; next-level-cache = <&A53_L2>; cpu-idle-states = <&CPU_SLEEP_0 &CLUSTER_SLEEP_0>; capacity-dmips-mhz = <592>; clocks = <&stub_clock HI3660_CLK_STUB_CLUSTER0>; operating-points-v2 = <&cluster0_opp>; #cooling-cells = <2>; dynamic-power-coefficient = <110>; };
cpu1: cpu@1 { compatible = "arm,cortex-a53", "arm,armv8"; device_type = "cpu"; reg = <0x0 0x1>; enable-method = "psci"; next-level-cache = <&A53_L2>; cpu-idle-states = <&CPU_SLEEP_0 &CLUSTER_SLEEP_0>; capacity-dmips-mhz = <592>; clocks = <&stub_clock HI3660_CLK_STUB_CLUSTER0>; operating-points-v2 = <&cluster0_opp>; };
cpu2: cpu@2 { compatible = "arm,cortex-a53", "arm,armv8"; device_type = "cpu"; reg = <0x0 0x2>; enable-method = "psci"; next-level-cache = <&A53_L2>; cpu-idle-states = <&CPU_SLEEP_0 &CLUSTER_SLEEP_0>; capacity-dmips-mhz = <592>; clocks = <&stub_clock HI3660_CLK_STUB_CLUSTER0>; operating-points-v2 = <&cluster0_opp>; };
cpu3: cpu@3 { compatible = "arm,cortex-a53", "arm,armv8"; device_type = "cpu"; reg = <0x0 0x3>; enable-method = "psci"; next-level-cache = <&A53_L2>; cpu-idle-states = <&CPU_SLEEP_0 &CLUSTER_SLEEP_0>; capacity-dmips-mhz = <592>; clocks = <&stub_clock HI3660_CLK_STUB_CLUSTER0>; operating-points-v2 = <&cluster0_opp>; };
cpu4: cpu@100 { compatible = "arm,cortex-a73", "arm,armv8"; device_type = "cpu"; reg = <0x0 0x100>; enable-method = "psci"; next-level-cache = <&A73_L2>; cpu-idle-states = <&CPU_SLEEP_1 &CLUSTER_SLEEP_1>; capacity-dmips-mhz = <1024>; clocks = <&stub_clock HI3660_CLK_STUB_CLUSTER1>; operating-points-v2 = <&cluster1_opp>; #cooling-cells = <2>; dynamic-power-coefficient = <550>; };
cpu5: cpu@101 { compatible = "arm,cortex-a73", "arm,armv8"; device_type = "cpu"; reg = <0x0 0x101>; enable-method = "psci"; next-level-cache = <&A73_L2>; cpu-idle-states = <&CPU_SLEEP_1 &CLUSTER_SLEEP_1>; capacity-dmips-mhz = <1024>; clocks = <&stub_clock HI3660_CLK_STUB_CLUSTER1>; operating-points-v2 = <&cluster1_opp>; };
cpu6: cpu@102 { compatible = "arm,cortex-a73", "arm,armv8"; device_type = "cpu"; reg = <0x0 0x102>; enable-method = "psci"; next-level-cache = <&A73_L2>; cpu-idle-states = <&CPU_SLEEP_1 &CLUSTER_SLEEP_1>; capacity-dmips-mhz = <1024>; clocks = <&stub_clock HI3660_CLK_STUB_CLUSTER1>; operating-points-v2 = <&cluster1_opp>; };
cpu7: cpu@103 { compatible = "arm,cortex-a73", "arm,armv8"; device_type = "cpu"; reg = <0x0 0x103>; enable-method = "psci"; next-level-cache = <&A73_L2>; cpu-idle-states = <&CPU_SLEEP_1 &CLUSTER_SLEEP_1>; capacity-dmips-mhz = <1024>; clocks = <&stub_clock HI3660_CLK_STUB_CLUSTER1>; operating-points-v2 = <&cluster1_opp>; };
idle-states { entry-method = "psci";
CPU_SLEEP_0: cpu-sleep-0 { compatible = "arm,idle-state"; local-timer-stop; arm,psci-suspend-param = <0x0010000>; entry-latency-us = <400>; exit-latency-us = <650>; min-residency-us = <1500>; }; CLUSTER_SLEEP_0: cluster-sleep-0 { compatible = "arm,idle-state"; local-timer-stop; arm,psci-suspend-param = <0x1010000>; entry-latency-us = <500>; exit-latency-us = <1600>; min-residency-us = <3500>; };
CPU_SLEEP_1: cpu-sleep-1 { compatible = "arm,idle-state"; local-timer-stop; arm,psci-suspend-param = <0x0010000>; entry-latency-us = <400>; exit-latency-us = <550>; min-residency-us = <1500>; };
CLUSTER_SLEEP_1: cluster-sleep-1 { compatible = "arm,idle-state"; local-timer-stop; arm,psci-suspend-param = <0x1010000>; entry-latency-us = <800>; exit-latency-us = <2900>; min-residency-us = <3500>; }; };
A53_L2: l2-cache0 { compatible = "cache"; };
A73_L2: l2-cache1 { compatible = "cache"; }; }; |
3.2 几个辅助的全局变量
|
struct cpu_topology { int thread_id; int core_id; int package_id; int llc_id; cpumask_t thread_sibling; //在同一个core下的thread cpumask_t core_sibling; //在同一个cluster下的core cpumask_t llc_sibling; //共享L2 Cache的cluster };
extern struct cpu_topology cpu_topology[NR_CPUS];
#define topology_physical_package_id(cpu) (cpu_topology[cpu].package_id) #define topology_core_id(cpu) (cpu_topology[cpu].core_id) #define topology_core_cpumask(cpu) (&cpu_topology[cpu].core_sibling) #define topology_sibling_cpumask(cpu) (&cpu_topology[cpu].thread_sibling) #define topology_llc_cpumask(cpu) (&cpu_topology[cpu].llc_sibling) |
注意:NR_CPUS表示逻辑cpu的个数,也就是thread的个数,而不是物理cpu的个数,如果cpu支持超线程的话,物理cpu个数=逻辑cpu个数*2
3.3 parse_dt_topology - 从设备树中解析出cpu的算力
文件位置:arch\arm64\kernel\topology.c
|
static int __init parse_dt_topology(void) { struct device_node *cn, *map; int ret = 0; int cpu;
//1.从根节点找到cpu节点 cn = of_find_node_by_path("/cpus"); if (!cn) { pr_err("No CPU information found in DT\n"); return 0; }
/* * When topology is provided cpu-map is essentially a root * cluster with restricted subnodes. */ //2.向下找到cpu-map节点 map = of_get_child_by_name(cn, "cpu-map"); if (!map) goto out;
//3.从上面的设备树中解析得到cluster信息,并为各个cpu计算算力 ret = parse_cluster(map, 0); if (ret != 0) goto out_map;
//4.向大核、1024进行归一化,计算得到各个cpu的算力值, // 并保存进各个cpu的percpu变量中 topology_normalize_cpu_scale();
/* * Check that all cores are in the topology; the SMP code will * only mark cores described in the DT as possible. */ //5.校验是不是所有的cpu都已经在拓扑结构中了 for_each_possible_cpu(cpu) { if (cpu_topology[cpu].package_id == -1) ret = -EINVAL; }
out_map: of_node_put(map); out: of_node_put(cn); return ret; } |
3.4 parse_cluster - 解析设备树中的cluster信息
注意:该函数会多次重入,分析该函数时请结合上面设备树的格式看
实现位置:arch\arm64\kernel\topology.c
|
static int __init parse_cluster( struct device_node *cluster, //第一次传入cpu-map设备树对于的节点, //第二次传入cluster对应的节点 int depth) //当前节点的深度,cpu-map节点对应的深度为0 //之后每向下一级,depth+1 { char name[10]; bool leaf = true; bool has_cores = false; struct device_node *c; static int package_id __initdata; //static类型的变量,用于记录cluster id int core_id = 0; //局部变量,每个cluster中的core计数从0开始 int i, ret;
/* * First check for child clusters; we currently ignore any * information about the nesting of clusters and present the * scheduler with a flat list of them. */ //1.第一次调用该函数的时候,传入的参数cluster指向cpu-map节点 // 第二次重入该函数的时候,传入的参数cluster指向cluster0节点 // 如果在设备树中的cluster节点下面还有一个子cluster节点,则需 // 要重入parse_cluster函数,向下一级解析cluster节点 // 另外,因为下面的循环是do-while循环,因此parse_cluster一定会被重入 i = 0; do { //1.1 获取cluster节点对应的设备树node snprintf(name, sizeof(name), "cluster%d", i); c = of_get_child_by_name(cluster, name);
if (c) { //1.2 这里的leaf用于标记当前正在遍历的这个cluster节点,是不是 // 最后一级cluster节点,为true时表示是最后一级,为flase时 // 表示不是最后一级,也就是说还存在子cluster节点 leaf = false;
//1.3 当第一次调用该函数的时候,一定能在cpu-map节点下找到一个 // 名为cluster0的节点,c就是指向这个cluster0节点。之后继 // 续重入parse_cluster函数,检查在cluster0下面是否还会存 // 在一个名为cluster的子节点 ret = parse_cluster(c, depth + 1); of_node_put(c); if (ret != 0) return ret; } i++; } while (c);
/* Now check for cores */ //2.在第二次重入的时候,在下面的循环中解析cluster下面的所有core属性 i = 0; do { snprintf(name, sizeof(name), "core%d", i); c = of_get_child_by_name(cluster, name);
if (c) { //2.1 标记已经找到了一个core节点了 has_cores = true;
//2.2 对设备树的格式的校验,core只能是在cluster节点下, // 第二次重入的时候,depth一定不是0 if (depth == 0) { pr_err("%pOF: cpu-map children should be clusters\n", c); of_node_put(c); return -EINVAL; }
//2.3 由上面的逻辑可知,leaf用于标记当前正在处理的cluster是不是最 // 后一级cluster,该分支表示解析最后一级cluster中的core节点 if (leaf) { ret = parse_core(c, package_id, core_id++); } else { pr_err("%pOF: Non-leaf cluster with core %s\n", cluster, name); ret = -EINVAL; }
of_node_put(c); if (ret != 0) return ret; } //2.4 遍历下一个core节点 i++; } while (c);
if (leaf && !has_cores) pr_warn("%pOF: empty cluster\n", cluster);
//3.代码走到这里,说明当前正在遍历的这个cluster下的所有core节点已经解析完毕, // 此时将static类型的变量package_id执行加加操作,该变量用于给系统中所有的 // cluster进行编号,由此可见,系统中的所有cluster是统一编号的 if (leaf) package_id++;
return 0; } |
3.5 parse_core - 解析设备树中的core信息
实现位置:arch\arm64\kernel\topology.c
|
static int __init parse_core( struct device_node *core, //core指向的节点 int package_id, //当前正在遍历的cluster节点,在系统中的编号 int core_id) //当前正在遍历的core节点,在本cluster中的编号 { char name[10]; bool leaf = true; int i = 0; int cpu; struct device_node *t;
do { //1.如果在core节点下还存在thread层级,也就是说可以超线程, // 则继续解析thread节点,一般在arm和arm64中不存在超线程, // 也就不存在thread节点了 snprintf(name, sizeof(name), "thread%d", i); t = of_get_child_by_name(core, name);
if (t) { //1.1 leaf用于标记当前正在遍历的core节点是不是叶子节点, // 代码走到这里,说明真的存在thread节点,正在遍历的core // 当然也就不是叶子节点了,此时将其置为false leaf = false;
//1.2 解析thread节点中的capacity-dmips-mhz信息,并返回对应的cpu号 cpu = get_cpu_for_node(t); if (cpu >= 0) { //1.3 记录拓扑信息 cpu_topology[cpu].package_id = package_id; //记录这个thread所属的cluster编号 cpu_topology[cpu].core_id = core_id; //记录这个thread所属的core编号 cpu_topology[cpu].thread_id = i; //给这个thread进行编号 } else { pr_err("%pOF: Can't get CPU for thread\n", t); of_node_put(t); return -EINVAL; } of_node_put(t); } //1.4 处理下一个thread i++; } while (t);
//2.解析core接线中的capacity-dmips-mhz信息 cpu = get_cpu_for_node(core); if (cpu >= 0) { //2.1 由下面的报错信息可知,设备树中不能同时存在thread和cpu节点 if (!leaf) { pr_err("%pOF: Core has both threads and CPU\n", core); return -EINVAL; }
//2.2 在拓扑结构中记录当前core节点的所属cluster和coreid cpu_topology[cpu].package_id = package_id; //当前core节点所属cluster cpu_topology[cpu].core_id = core_id; //当前core节点的id } else if (leaf) { pr_err("%pOF: Can't get CPU for leaf core\n", core); return -EINVAL; }
return 0; } |
3.6 get_cpu_for_node - 解析capacity-dmips-mhz属性
实现位置:arch\arm64\kernel\topology.c
|
static int __init get_cpu_for_node( struct device_node *node) //可能指向thread节点,也可能指向core节点 { struct device_node *cpu_node; int cpu;
//1.首先获取对cpu的应用 cpu_node = of_parse_phandle(node, "cpu", 0); if (!cpu_node) return -1;
//2.获取引用的cpu节点的id号 cpu = of_cpu_node_to_id(cpu_node); if (cpu >= 0) //2.1 解析被引用的cpu节点中的capacity-dmips-mhz属性 topology_parse_cpu_capacity(cpu_node, cpu); else pr_crit("Unable to find CPU node for %pOF\n", cpu_node);
of_node_put(cpu_node); return cpu; } |
3.7 topology_parse_cpu_capacity - 解析capacity-dmips-mhz的值并赋给raw_capacity[]
从设备数中获取capacity-dmips-mhz属性的值,并赋值给raw_capacity[]全局变量,该值是cpu在1Mhz频率下的dmpis,后面即使cpu的频率发生变化,该值也不会改变
注意,该函数获取成功后返回1
实现位置:U:\linux-5.10.61\drivers\base\arch_topology.c
|
bool __init topology_parse_cpu_capacity( struct device_node *cpu_node, //要解析的cpu节点 int cpu) //当前cpu节点对应的cpu编号 { struct clk *cpu_clk;
//1.static类型的变量,默认初始化为0,即false // 该变量标记cpu的原始算力值capacity-dmips-mhz解析失败 static bool cap_parsing_failed; int ret; u32 cpu_capacity;
//2.使用该static变量的目的是:只要有一个节点的capacity-dmips-mhz属性解析 // 失败,就不需要再执行下面的操作了,直接返回,标记整个系统的算力计算失败了 if (cap_parsing_failed) return false;
//3.从设备树中读出capacity-dmips-mhz属性的值,并赋值给raw_capacity[] ret = of_property_read_u32(cpu_node, "capacity-dmips-mhz", &cpu_capacity); if (!ret) { //3.1 为raw_capacity申请空间 if (!raw_capacity) { raw_capacity = kcalloc(num_possible_cpus(), sizeof(*raw_capacity), GFP_KERNEL); if (!raw_capacity) { cap_parsing_failed = true; return false; } }
//3.2 赋值给全局变量raw_capacity[] raw_capacity[cpu] = cpu_capacity; pr_debug("cpu_capacity: %pOF cpu_capacity=%u (raw)\n", cpu_node, raw_capacity[cpu]);
/* * Update freq_factor for calculating early boot cpu capacities. * For non-clk CPU DVFS mechanism, there's no way to get the * frequency value now, assuming they are running at the same * frequency (by keeping the initial freq_factor value). */ //3.3 上面获取得到的是1MHz下的cpu算力,我们在做归一化的时候, // 需要向最大核的最高频做归一化,这里,这里先记录下各个cpu的 // 实际工作频率,在后面归一化的时候使用 cpu_clk = of_clk_get(cpu_node, 0); if (!PTR_ERR_OR_ZERO(cpu_clk)) { per_cpu(freq_factor, cpu) = clk_get_rate(cpu_clk) / 1000; clk_put(cpu_clk); } } else { //4.代码走到这,说明当前正在遍历的这个cpu节点中不存在capacity-dmips-mhz属性 // 此时算力计算失败啊 if (raw_capacity) { pr_err("cpu_capacity: missing %pOF raw capacity\n",cpu_node); pr_err("cpu_capacity: partial information: fallback to 1024 for all CPUs\n"); } cap_parsing_failed = true; free_raw_capacity(); } //4.获取成功返回1 return !ret; } |
3.8 topology_normalize_cpu_scale - 向最大核做归一化处理,得到的cpu算力赋值给cpu_scale全局变量
上面已经解析出各个cpu的capacity-dmips-mhz值,下面需要向最大核做归一化处理,并保存进percpu变量cpu_scale。归一化后,最大核对应的cpu_scale为1024,计算公式如下
|
raw_capacity[cpu] cpu_scale[cpu] = ------------------------------ * 1024 MAX(raw_capacity[0..NR_CPUS]) |
该函数会在初始化的时候,和policy刚创建的时候调用
实现位置:U:\linux-5.10.61\drivers\base\arch_topology.c
|
void topology_normalize_cpu_scale(void) { u64 capacity; u64 capacity_scale; int cpu;
//1.该变量记录着从设备树中读取到的capacity-dmips-mhz值 if (!raw_capacity) return;
//2.因为我们要向最大核的最高频做归一化处理,所以这里先记录下最大核在最高频率 // 下的dmips,(dmips = dmips_mhz * freq),需要注意的是,该函数会在初始 // 化和policy刚创建的时候调用,当policy刚创建的时候,freq_factor会被设置 // 为policy->cpuinfo.max_freq,也就是这个policy所能达到的最高频率,(这 // 个最高频率是不受限频的影响的),所以下面循环中第一个式子可理解为计算这个 // cpu在最高频率时的dmips,而第二个式子就是将系统中最大核最高频的dmips记录 // 在capacity_scale中,以便后面向其做归一化 capacity_scale = 1; for_each_possible_cpu(cpu) { capacity = raw_capacity[cpu] * per_cpu(freq_factor, cpu); capacity_scale = max(capacity, capacity_scale); }
pr_debug("cpu_capacity: capacity_scale=%llu\n", capacity_scale);
//3.为每个cpu计算归一化的算力值,并赋值给percpu变量cpu_scale for_each_possible_cpu(cpu) { //3.1 下面两步就是向最大核的最高频做归一化处理 // 第一步:计算dmips,dmips = dmpis_mhz * freq // 第二步:向最大核的最高频做归一化处理,左移10bit表示乘以1024, // 这就表示了向1024做归一化处理,最大核的最高频就是1024 capacity = raw_capacity[cpu] * per_cpu(freq_factor, cpu); capacity = div64_u64(capacity << SCHED_CAPACITY_SHIFT, capacity_scale);
//3.2 将归一化的值记录在percpu变量cpu_scale中 topology_set_cpu_scale(cpu, capacity); pr_debug("cpu_capacity: CPU%d cpu_capacity=%lu\n", cpu, topology_get_cpu_scale(cpu)); } } |
3.9 当policy结构中的成员发生变化时,向最高频做归一化
3.9.1 通知链的注册 - 当policy结构中的成员发生变化时调用回调函数
CPUFREQ_POLICY_NOTIFIER类型的通知,表示当policy结构中的成员发生变化时,调用回调函数
|
static struct notifier_block init_cpu_capacity_notifier = { .notifier_call = init_cpu_capacity_callback, };
static int __init register_cpufreq_notifier(void) { ...
//1.注册CPUFREQ_POLICY_NOTIFIER类型的notify, // 该类型的notify在policy结构中的成员发生变化时发送通知 ret = cpufreq_register_notifier(&init_cpu_capacity_notifier, CPUFREQ_POLICY_NOTIFIER);
... } core_initcall(register_cpufreq_notifier); |
3.9.2 init_cpu_capacity_callback - 当policy结构中的成员发生变化时,重新设置cpu_scale的值
cpu_scale的值表示的是"这个cpu工作在最大频率时的算力",(注意:这里说的最高频是指policy->cpuinfo.max_freq,这个值是不受限频的影响的),当然这个算力是向最大核的最高频做1024归一化后的值
实现位置:U:\linux-5.10.61\drivers\base\arch_topology.c
|
static int init_cpu_capacity_callback( struct notifier_block *nb, unsigned long val, void *data) { struct cpufreq_policy *policy = data; int cpu;
//1.若为空,则说面前面没有从设备树中获取capacity-dmips-mhz信息,则返回 if (!raw_capacity) return 0;
//2.确保是在policy刚开始创建的时候发起通知 // 一方面:因为在policy刚创建的时候就已经确定了这个policy所能达到的 // 最高频policy->cpuinfo.max_freq,该值后面不会改变,直接在 // 这个时机做归一化是最合适的了 // 另一方面:因为我们只关注policy->cpuinfo.max_freq,虽然正常的调频 // 限频操作也会触发这个回调函数,但是我们并不关注,也就没必要 // 执行下面的逻辑了,直接返回 if (val != CPUFREQ_CREATE_POLICY) return 0;
pr_debug("cpu_capacity: init cpu capacity for CPUs [%*pbl] (to_visit=%*pbl)\n", cpumask_pr_args(policy->related_cpus), cpumask_pr_args(cpus_to_visit));
//3.注意这里的逻辑,cpus_to_visit变量初始化的时候为cpu_possible_mask, // 每当有cluster新创建policy时,就将这个cluster中的所有cpu从这个 // cpus_to_visit中移除,当所有cluster对应的policy都创建完毕后, // cpus_to_visit为空,这样下面第5步的归一化处理就不用每次都执行了 cpumask_andnot(cpus_to_visit, cpus_to_visit, policy->related_cpus);
//4.获取正在创建的这个policy所能达到的最高频率, // 并记录到freq_factor中,以便后面归一化使用 for_each_cpu(cpu, policy->related_cpus) per_cpu(freq_factor, cpu) = policy->cpuinfo.max_freq / 1000;
//5.向最大核的最高频做归一化处理 // 这里的if条件表示:如果系统中所有cpu都完成了 // 归一化操作,就不需要再进行下面的归一化操作了 if (cpumask_empty(cpus_to_visit)) { topology_normalize_cpu_scale(); schedule_work(&update_topology_flags_work); free_raw_capacity(); pr_debug("cpu_capacity: parsing done\n"); schedule_work(&parsing_done_work); }
return 0; } |
四、ARM32解析设备树
arm32有两种方法解析cpu算力,顺序依次为
方案一:通过设备树中的capacity-dmips-mhz属性
方案二:通过静态定义的算力表table_efficiency[]
4.1 arm32设备树信息
文件位置:arch\arm\boot\dts\exynos5420-cpus.dtsi
|
/ { cpus { #address-cells = <1>; #size-cells = <0>;
cpu0: cpu@0 { device_type = "cpu"; compatible = "arm,cortex-a15"; reg = <0x0>; clocks = <&clock CLK_ARM_CLK>; clock-frequency = <1800000000>; cci-control-port = <&cci_control1>; operating-points-v2 = <&cluster_a15_opp_table>; #cooling-cells = <2>; /* min followed by max */ capacity-dmips-mhz = <1024>; };
cpu1: cpu@1 { device_type = "cpu"; compatible = "arm,cortex-a15"; reg = <0x1>; clocks = <&clock CLK_ARM_CLK>; clock-frequency = <1800000000>; cci-control-port = <&cci_control1>; operating-points-v2 = <&cluster_a15_opp_table>; #cooling-cells = <2>; /* min followed by max */ capacity-dmips-mhz = <1024>; };
cpu2: cpu@2 { device_type = "cpu"; compatible = "arm,cortex-a15"; reg = <0x2>; clocks = <&clock CLK_ARM_CLK>; clock-frequency = <1800000000>; cci-control-port = <&cci_control1>; operating-points-v2 = <&cluster_a15_opp_table>; #cooling-cells = <2>; /* min followed by max */ capacity-dmips-mhz = <1024>; };
cpu3: cpu@3 { device_type = "cpu"; compatible = "arm,cortex-a15"; reg = <0x3>; clocks = <&clock CLK_ARM_CLK>; clock-frequency = <1800000000>; cci-control-port = <&cci_control1>; operating-points-v2 = <&cluster_a15_opp_table>; #cooling-cells = <2>; /* min followed by max */ capacity-dmips-mhz = <1024>; };
cpu4: cpu@100 { device_type = "cpu"; compatible = "arm,cortex-a7"; reg = <0x100>; clocks = <&clock CLK_KFC_CLK>; clock-frequency = <1000000000>; cci-control-port = <&cci_control0>; operating-points-v2 = <&cluster_a7_opp_table>; #cooling-cells = <2>; /* min followed by max */ capacity-dmips-mhz = <539>; };
cpu5: cpu@101 { device_type = "cpu"; compatible = "arm,cortex-a7"; reg = <0x101>; clocks = <&clock CLK_KFC_CLK>; clock-frequency = <1000000000>; cci-control-port = <&cci_control0>; operating-points-v2 = <&cluster_a7_opp_table>; #cooling-cells = <2>; /* min followed by max */ capacity-dmips-mhz = <539>; };
cpu6: cpu@102 { device_type = "cpu"; compatible = "arm,cortex-a7"; reg = <0x102>; clocks = <&clock CLK_KFC_CLK>; clock-frequency = <1000000000>; cci-control-port = <&cci_control0>; operating-points-v2 = <&cluster_a7_opp_table>; #cooling-cells = <2>; /* min followed by max */ capacity-dmips-mhz = <539>; };
cpu7: cpu@103 { device_type = "cpu"; compatible = "arm,cortex-a7"; reg = <0x103>; clocks = <&clock CLK_KFC_CLK>; clock-frequency = <1000000000>; cci-control-port = <&cci_control0>; operating-points-v2 = <&cluster_a7_opp_table>; #cooling-cells = <2>; /* min followed by max */ capacity-dmips-mhz = <539>; }; }; }; |
4.2 几个辅助的全局变量
在分析该函数实现之前,先看一下该函数中会使用到的一些辅助的全局变量,这几个全局变量主要用于实现方案二:
|
struct cpu_efficiency { const char *compatible; unsigned long efficiency; };
/* * Table of relative efficiency of each processors * The efficiency value must fit in 20bit and the final * cpu_scale value must be in the range * 0 < cpu_scale < 3*SCHED_CAPACITY_SCALE/2 * in order to return at most 1 when DIV_ROUND_CLOSEST * is used to compute the capacity of a CPU.
* use the default SCHED_CAPACITY_SCALE value for cpu_scale. */ //下面的变量是厂商在1MHz的频率下,对这个cpu测量出来的效率值,类似于dmips-mhz //但是linux中保留的算力值,是相对于这个cpu最高频的,所以在代码中还需要 //结合这个cpu的最高工作频率,(即设备树中的clock-frequency属性),来 //重新计算这个cpu的最高效率值 //由上面的注释可知,对于不在下面表中的cpu,默认效率值为1024 static const struct cpu_efficiency table_efficiency[] = { {"arm,cortex-a15", 3891}, {"arm,cortex-a7", 2048}, {NULL, }, };
static unsigned long *__cpu_capacity; #define cpu_capacity(cpu) __cpu_capacity[cpu]
static unsigned long middle_capacity = 1; static bool cap_from_dt = true; |
4.3 parse_dt_topology - 从设备树中解析出cpu的算力
该函数在创建cpu的拓扑结构的时候被调用,也就是在创建cpu的拓扑结构的时候计算cpu的算力
调用关系:start_kernel -> rest_init -> kernel_init -> kernel_init_freeable -> smp_prepare_cpus -> init_cpu_topology -> parse_dt_topology
函数位置:arch/arm/kernel/topology.c
|
/* * Iterate all CPUs' descriptor in DT and compute the efficiency * (as per table_efficiency). Also calculate a middle efficiency * as close as possible to (max{eff_i} - min{eff_i}) / 2 * This is later used to scale the cpu_capacity field such that an * 'average' CPU is of middle capacity. Also see the comments near * table_efficiency[] and update_cpu_capacity(). */ static void __init parse_dt_topology(void) { const struct cpu_efficiency *cpu_eff; struct device_node *cn = NULL; unsigned long min_capacity = ULONG_MAX; unsigned long max_capacity = 0; unsigned long capacity = 0; int cpu = 0;
//1.申请空间 __cpu_capacity = kcalloc(nr_cpu_ids, sizeof(*__cpu_capacity), GFP_NOWAIT);
cn = of_find_node_by_path("/cpus"); if (!cn) { pr_err("No CPU information found in DT\n"); return; }
for_each_possible_cpu(cpu) { const u32 *rate; int len;
/* too early to use cpu->of_node */ //2.获取指定cpu的设备树 cn = of_get_cpu_node(cpu, NULL); if (!cn) { pr_err("missing device node for CPU %d\n", cpu); continue; }
//3.首先尝试方法一:使用设备树中获取capacity-dmips-mhz属性的值来计算算力 // 并赋值给raw_capacity[]全局变量,解析成功后就直接continue了,不会继续向下 if (topology_parse_cpu_capacity(cn, cpu)) { of_node_put(cn); continue; }
//4.只有在上面方法一获取失败,才会走到这里,继续向下使用方法二计算算力 // 注意:只要有一个cpu获取capacity-dmips-mhz属性失败,就将这个开关 // 置为false,后面就不使用从设备树中获取到的参数了 cap_from_dt = false;
//5.注意:代码走到这里,说明上面从设备树中获取capacity-dmips-mhz属性失败, // 后面也就不能通过capacity-dmips-mhz计算cpu的算力,转而使用系统中预先 // 设置好的cpu的效率值计算 // 原理:cpu厂商已经计算出一组各种cpu在1MHz下的效率值,类似于dmips-mhz // 并保存在全局数组变量table_efficiency中,但是这个值是在1MHz频率下计算出来的, // 实际Linux中保留的算力的值都是相对于这个cpu的最高频率的,因此,该值还需要和 // 这个cpu的最高频率进行一次运算,才能得到cpu在最高频时的效率值
//5.1 通过比对设备树中的compatible属性,在table_efficiency中找到当前正在遍历 // 的cpu对应的efficiency值 // of_device_is_compatible不匹配返回0,成功匹配返回非0值 for (cpu_eff = table_efficiency; cpu_eff->compatible; cpu_eff++) { if (of_device_is_compatible(cn, cpu_eff->compatible)) break; } //5.2 如果表中没有和这个cpu匹配的效率值,直接跳过,后面默认会使用1024 if (cpu_eff->compatible == NULL) continue;
//5.3 解析clock-frequency属性,即cpu的最高频率 rate = of_get_property(cn, "clock-frequency", &len); if (!rate || len != 4) { pr_err("%pOF missing clock-frequency property\n", cn); continue; }
//5.4 cpu_eff->efficiency是厂商在1mhz下测试出来的效率值,类似dmips-mhz, // 下面需要根据这个cpu的最高频率,计算得到最高频下的效率值,方法如下: // 首先将设备树中的频率单位转化为MHz,然后乘以cpu_eff->efficiency capacity = ((be32_to_cpup(rate)) >> 20) * cpu_eff->efficiency;
//6.记录算力的最大和最小值以便后面计算middle_capacity /* Save min capacity of the system */ if (capacity < min_capacity) min_capacity = capacity;
/* Save max capacity of the system */ if (capacity > max_capacity) max_capacity = capacity;
//7.设置中间变量__cpu_capacity[cpu],保存各个cpu的算力 cpu_capacity(cpu) = capacity; }
/* If min and max capacities are equals, we bypass the update of the * cpu_scale because all CPUs have the same capacity. Otherwise, we * compute a middle_capacity factor that will ensure that the capacity * of an 'average' CPU of the system will be as close as possible to * SCHED_CAPACITY_SCALE, which is the default value, but with the * constraint explained near table_efficiency[]. */ //11.当使用方案2计算cpu算力时,需要找出一个基准算力值,然后所有cpu的算力向 // 这个基准算力做归一化处理,这个基准算力值选取逻辑是: // a) 当max < 3min的时候,此时我们认为min和max差距不是很大, // 此时选取min和max的中间值作为基准算力 // b) 当max > 3min的时候,此时min和max值之间的差距还是很大的, // 以至于min可以被忽略,此时直接使用max的2/3作为基准算力 if (4*max_capacity < (3*(max_capacity + min_capacity))) middle_capacity = (min_capacity + max_capacity) >> (SCHED_CAPACITY_SHIFT+1); else middle_capacity = ((max_capacity / 3) >> (SCHED_CAPACITY_SHIFT-1)) + 1;
//12.如果上面从设备树中成功获取到capacity-dmips-mhz属性,也就是使用方法一计算cpu算力时 // 则执行下面通用函数完成归一化的处理,方法二则不需要进行归一化处理 if (cap_from_dt) topology_normalize_cpu_scale(); } |
4.4 update_cpu_capacity - 向最高频做归一化,并赋值给cpu_scale
只适用于方法二,向基准效率值进行归一化处理
调用路径:store_cpu_topology -> update_cpu_capacity
函数位置:arch\arm\kernel\topology.c
|
/* * Look for a customed capacity of a CPU in the cpu_capacity table during the * boot. The update of all CPUs is in O(n^2) for heteregeneous system but the * function returns directly for SMP system. */ static void update_cpu_capacity(unsigned int cpu) { //1.如果使用方法一,也就是通过设备树计算算力值时,cap_from_dt为true,直接返回 // 如果是使用方法二,即使用预先设置好的一组效率值,cap_from_dt为false,则执行下面的操作, // 类似归一化的操作 if (!cpu_capacity(cpu) || cap_from_dt) return;
//2.对于方法二,下面计算得到真正的算力,并保存进percpu变量 // middle_capacity的默认值为1,当使用方法一,通过设备数获取cpu算力的时候,该值始终为1 // 当使用方法二,通过预设的cpu效率值计算cpu算力时,该值由计算得到 topology_set_cpu_scale(cpu, cpu_capacity(cpu) / middle_capacity);
pr_info("CPU%u: update cpu_capacity %lu\n", cpu, topology_get_cpu_scale(NULL, cpu)); } |
五、判断一个cpu的剩余算力是否满足一个task的需求
5.1 update_misfit_status
|
static inline void update_misfit_status(struct task_struct *p, struct rq *rq) { if (!static_branch_unlikely(&sched_asym_cpucapacity)) return;
//1.如果这个task被绑核了,则无需执行下面的判断 if (!p || p->nr_cpus_allowed == 1) { rq->misfit_task_load = 0; return; }
//2.检查这个cpu的剩余算力是否能够满足这个task的需求 if (task_fits_capacity(p, capacity_of(cpu_of(rq)))) { rq->misfit_task_load = 0; return; }
/* * Make sure that misfit_task_load will not be null even if * task_h_load() returns 0. */ //3.misfit_task_load非0表示这个cpu已经超载了 rq->misfit_task_load = max_t(unsigned long, task_h_load(p), 1); } |
5.2 task_fits_capacity - 判断一个cpu的剩余算力是否能够满足task的需求
如果这个task的util值小于cpu的剩余算力的80%时,表示是filt的,超过80%则表示这个task不适合放到这个cpu上
|
static inline int task_fits_capacity( struct task_struct *p, long capacity) //这个capacity表示cpu的剩余算力 { return fits_capacity(uclamp_task_util(p), capacity); } |
其中:
|
/* * The margin used when comparing utilization with CPU capacity. * * (default: ~20%) */ #define fits_capacity(cap, max) ((cap) * 1280 < (max) * 1024) |

文章评论
nubility