关注公众号不迷路:DumpStack
扫码加关注

目录
- 一、开胃小菜
- 二、0号、1号、2号进程的创建
- 三、idle线程要完成的工作
- 四、本章涉及函数
- 关注公众号不迷路:DumpStack
本文分析基于Linux-5.10.61
参考文档:
https://www.sohu.com/a/486295565_121124374
https://blog.csdn.net/feelabclihu/article/details/106866457
https://blog.csdn.net/jacobywu/article/details/78818284
http://www.wowotech.net/tag/cpuidle
一、开胃小菜
注:下文摘自蜗窝科技,向大牛们致敬
cpu为什么要进入idle?怎样进入idle?
在计算机系统中,CPU的功能是执行程序,总结起来就是我们在教科书上学到的:取指、译码、执行。那么问题来了,如果没有程序要执行,CPU要怎么办?也许您会说,停掉就是了啊。确实,是要停掉,但何时停、怎么停,却要仔细斟酌,因为实际的软硬件环境是非常复杂的。
Linux系统中,CPU被两类程序占用:一类是进程(或线程),也称进程上下文;另一类是各种中断、异常的处理程序,也称中断上下文。
进程的存在,是用来处理事务的,如读取用户输入并显示在屏幕上。而事务总有处理完的时候,如用户不再输入,也没有新的内容需要在屏幕上显示。此时这个进程就可以让出CPU,但会随时准备回来(如用户突然有按键动作)。同理,如果系统没有中断、异常事件,CPU就不会花时间在中断上下文。
在Linux kernel中,这种CPU的无所事事的状态,被称作idle状态,而cpuidle framework,就是为了管理这种状态。
曾经有过一段时间,Linux kernel的cpu idle框架是非常简单的,简单到driver工程师只需要在"include\asm-arm\arch-xxx\system.h"中定义一个名字为arch_idle的inline函数,并在该函数中调用kernel提供的cpu_do_idle接口,就Ok了,剩下的实现kernel全部帮我们做了,如下:
|
static inline void arch_idle(void) { cpu_do_idle(); } |
以蜗蜗之前使用过的一个ARM926的单核CPU为例(内核版本为Linux2.6.23),cpuidle的处理过程是:
|
start_kernel(arch\arm\kernel\head-common.S) start_kernel->rest_init(init\main.c) ;系统初始化完成后,将第一个进程(init)变为idle进程, ;以下都是在进程的循环中,周而复始… cpu_idle->default_idle(arch\arm\kernel\process.c) arch_idle(include\asm-arm\arch-xxx\system.h) cpu_do_idle(include/asm-arm/cpu-single.h) cpu_arm926_do_idle(arch/arm/mm/proc-arm926.S) mcr p15, 0, r0, c7, c0, 4 @ Wait for interrupt ;WFI指令 |
虽然简单,却包含了idle处理的两个重点:
1)idle进程
idle进程的存在,是为了解决"何时idle"的问题。
我们知道,Linux系统运行的基础是进程调度,而所有进程都不再运行时,称作cpu idle。但是,怎么判断这种状态呢?kernel采用了一个比较简单的方法:在init进程(系统的第一个进程init_task)完成初始化任务之后,将其转变为idle进程,由于该进程的优先级是最低的,所以当idle进程被调度到时,则说明系统的其它进程不再运行了,也即CPU idle了。最终,由idle进程调用idle指令(这里为WFI),让CPU进入idle状态。
WFI Wakeup events会把CPU从WFI状态唤醒,通常情况下,这些events是一些中断事件,因此CPU唤醒后会执行中断handler,在handler中会wakeup某些进程,在handler返回的时候进行调度,当没有其他进程需要调度执行的时候,调度器会恢复idle进程的执行,当然,idle进程不做什么,继续进入idle状态,等待下一次的wakeup
2)WFI
WFI用于解决"怎么idle"的问题。
一般情况下,ARM CPU idle时,可以使用WFI指令,把CPU置为Wait for interrupt状态。该状态下,至少(和具体ARM core的实现有关)会把ARM core的clock关闭,以节省功耗。
也许您会觉得,上面的过程挺好了,为什么还要开发cpuide framework?蜗蜗的理解是:
ARM CPU的设计越来越复杂,对省电的要求也越来越苛刻,因而很多CPU会从"退出时的延迟"和"idle状态下的功耗"两个方面考虑,设计多种idle级别。对延迟较敏感的场合,可以使用低延迟、高功耗的idle;对延迟不敏感的场合,可以使用高延迟、低功耗的idle。
而软件则需要根据应用场景,在恰当的时候,选择一个合适的idle状态。而选择的策略是什么,就不是那么简单了。这就是cpuidle framework的存在意义(我们可以根据下面cpuidle framework的软件架构,佐证这一点)。
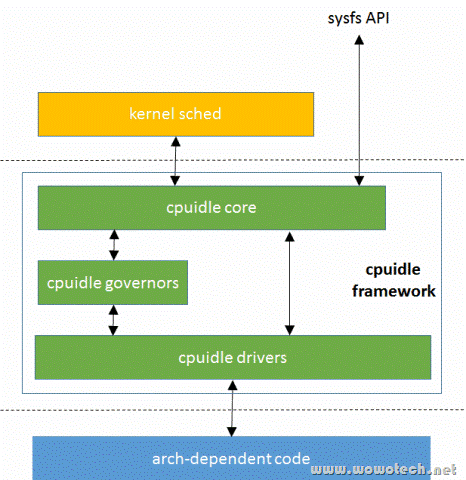
cpuidle子系统的软件框架如下图:
-
core层:提供一些api接口,idle线程通过调用这些接口,完成idle等级挑选、进入idle的工作
-
governor层:负责从众多的C state中,选择一个最合适当前系统状况的C state,很显然,不同的governor在选择C state时的判断标准不同
-
driver层:直接和硬件打交道,真正的将cpu置为指定的idle状态。这一步和cpu的架构相关,有的是通过设置系统寄存器实现、有的是通过小于指定的汇编指令实现、有的是通过SMC Calling实现,详细后面介绍
下面我们从分析idle线程完成的工作入手,来看一下系统在idle中需要完成哪些工作
二、0号、1号、2号进程的创建
参考文档:
https://www.cnblogs.com/alantu2018/p/8526970.html
https://www.cnblogs.com/mfrbuaa/p/5152800.html
https://www.freesion.com/article/54381112758/
Linux下有3个特殊的进程,idle进程(PID=0),init进程(PID=1)和kthreadd(PID=2)
-
idle:0号
idle进程的pid=0,由系统自动创建,运行在内核态,其前身是系统创建的第一个进程,也是唯一一个没有通过fork或者kernel_thread产生的进程,(确切的说,只有cpu0的idle是这么来的,其他cpu的idle是通过fork_idle来的)。在smp系统中,每个处理器单元有独立的一个运行队列,而每个运行队列上又有一个idle进程,即有多少处理器单元,就有多少idle进程。系统的空闲时间,其实就是指idle进程的"运行时间"
idle的运行时机
idle进程优先级为MAX_PRIO-20。早期版本中,idle是参与调度的,所以将其优先级设低点,当没有其他进程可以运行时,才会调度执行idle。而目前的版本中idle并不在运行队列中参与调度,而是在运行队列结构中含idle指针,指向idle进程,在调度器发现运行队列为空的时候运行,调入运行
-
init:1号
init进程由idle通过kernel_thread创建,在内核空间完成初始化后,加载用户空间的init程序,并最终进入用户空间,它是所有其它用户进程的祖宗,(通过pstree命令可查看)
注意:init线程的comm名还是swapper/0,和idle线程一样,这是因为init是由idle通过调用kernel_thread创建,但是kernel_thread是不会修改新创建的task的comm名的,只是从current(这里也就是调用者idle)复制一个task_struct结构
-
kthreadd:2号
kthreadd进程由idle通过kernel_thread创建,并始终运行在内核空间,负责所有内核线程的调度和管理,该进程会循环执行一个kthreadd的函数,该函数的作用就是运行kthread_create_list全局链表中维护的kthread,我们调用kernel_thread创建的内核线程都会被加入到此链表中,因此所有的内核线程都是直接或者间接的以kthreadd为父进程
2.1 init_task描述符 - 0号进程的task_struct结构
init_task是在init\init_task.c中静态定义的一个task_struct类型的数据结构,是内核中所有进程、线程的task_struct雏形,(因为所有线程都是直接或间接在0号线程中创建出来的,所以init_task数据结构决定了系统所有进程、线程的基因),它完成初始化后,最终演变为cpu0的0号进程idle,也就是说init_task作为0号线程的进程描述符,也是Linux系统中第一个进程描述符,后面会介绍0号线程是怎么和init_task关联起来的
init_task是Linux内核中的第一个线程,它贯穿于整个Linux系统的初始化过程中,该进程也是Linux系统中唯一一个没有用kernel_thread函数创建的内核线程。在init_task进程执行后期,它会调用kernel_thread函数创建第一个核心进程kernel_init,同时init_task进程继续对Linux系统初始化。在完成初始化后,init_task会转化为cpu0的idle进程
W:\opensource\linux-5.10.61\init\init_task.c
|
/* * Set up the first task table, touch at your own risk!. Base=0, * limit=0x1fffff (=2MB) */ struct task_struct init_task #ifdef CONFIG_ARCH_TASK_STRUCT_ON_STACK __init_task_data #endif __aligned(L1_CACHE_BYTES) = { #ifdef CONFIG_THREAD_INFO_IN_TASK .thread_info = INIT_THREAD_INFO(init_task), .stack_refcount = REFCOUNT_INIT(1), #endif .state = 0, .stack = init_stack, .usage = REFCOUNT_INIT(2), .flags = PF_KTHREAD, .prio = MAX_PRIO - 20, .static_prio = MAX_PRIO - 20, .normal_prio = MAX_PRIO - 20, .policy = SCHED_NORMAL, .cpus_ptr = &init_task.cpus_mask, .cpus_mask = CPU_MASK_ALL, .nr_cpus_allowed= NR_CPUS, .mm = NULL, .active_mm = &init_mm, .restart_block = { .fn = do_no_restart_syscall, }, .se = { .group_node = LIST_HEAD_INIT(init_task.se.group_node), }, .rt = { .run_list = LIST_HEAD_INIT(init_task.rt.run_list), .time_slice = RR_TIMESLICE, }, .tasks = LIST_HEAD_INIT(init_task.tasks), #ifdef CONFIG_SMP .pushable_tasks = PLIST_NODE_INIT(init_task.pushable_tasks, MAX_PRIO), #endif #ifdef CONFIG_CGROUP_SCHED .sched_task_group = &root_task_group, #endif .ptraced = LIST_HEAD_INIT(init_task.ptraced), .ptrace_entry = LIST_HEAD_INIT(init_task.ptrace_entry), .real_parent = &init_task, .parent = &init_task, .children = LIST_HEAD_INIT(init_task.children), //指向自己 .sibling = LIST_HEAD_INIT(init_task.sibling), .group_leader = &init_task, RCU_POINTER_INITIALIZER(real_cred, &init_cred), RCU_POINTER_INITIALIZER(cred, &init_cred), .comm = INIT_TASK_COMM, //这时候的comm还叫"swapper" .thread = INIT_THREAD, .fs = &init_fs, .files = &init_files, #ifdef CONFIG_IO_URING .io_uring = NULL, #endif .signal = &init_signals, .sighand = &init_sighand, .nsproxy = &init_nsproxy, .pending = { .list = LIST_HEAD_INIT(init_task.pending.list), .signal = {{0}} }, .blocked = {{0}}, .alloc_lock = __SPIN_LOCK_UNLOCKED(init_task.alloc_lock), .journal_info = NULL, INIT_CPU_TIMERS(init_task) .pi_lock = __RAW_SPIN_LOCK_UNLOCKED(init_task.pi_lock), .timer_slack_ns = 50000, /* 50 usec default slack */ .thread_pid = &init_struct_pid, //init_task对应的pid为0 .thread_group = LIST_HEAD_INIT(init_task.thread_group), .thread_node = LIST_HEAD_INIT(init_signals.thread_head), #ifdef CONFIG_AUDIT .loginuid = INVALID_UID, .sessionid = AUDIT_SID_UNSET, #endif #ifdef CONFIG_PERF_EVENTS .perf_event_mutex = __MUTEX_INITIALIZER(init_task.perf_event_mutex), .perf_event_list = LIST_HEAD_INIT(init_task.perf_event_list), #endif #ifdef CONFIG_PREEMPT_RCU .rcu_read_lock_nesting = 0, .rcu_read_unlock_special.s = 0, .rcu_node_entry = LIST_HEAD_INIT(init_task.rcu_node_entry), .rcu_blocked_node = NULL, #endif #ifdef CONFIG_TASKS_RCU .rcu_tasks_holdout = false, .rcu_tasks_holdout_list = LIST_HEAD_INIT(init_task.rcu_tasks_holdout_list), .rcu_tasks_idle_cpu = -1, #endif #ifdef CONFIG_TASKS_TRACE_RCU .trc_reader_nesting = 0, .trc_reader_special.s = 0, .trc_holdout_list = LIST_HEAD_INIT(init_task.trc_holdout_list), #endif #ifdef CONFIG_CPUSETS .mems_allowed_seq = SEQCNT_SPINLOCK_ZERO(init_task.mems_allowed_seq, &init_task.alloc_lock), #endif #ifdef CONFIG_RT_MUTEXES .pi_waiters = RB_ROOT_CACHED, .pi_top_task = NULL, #endif INIT_PREV_CPUTIME(init_task) #ifdef CONFIG_VIRT_CPU_ACCOUNTING_GEN .vtime.seqcount = SEQCNT_ZERO(init_task.vtime_seqcount), .vtime.starttime = 0, .vtime.state = VTIME_SYS, #endif #ifdef CONFIG_NUMA_BALANCING .numa_preferred_nid = NUMA_NO_NODE, .numa_group = NULL, .numa_faults = NULL, #endif #ifdef CONFIG_KASAN .kasan_depth = 1, #endif #ifdef CONFIG_KCSAN .kcsan_ctx = { .disable_count = 0, .atomic_next = 0, .atomic_nest_count = 0, .in_flat_atomic = false, .access_mask = 0, .scoped_accesses = {LIST_POISON1, NULL}, }, #endif #ifdef CONFIG_TRACE_IRQFLAGS .softirqs_enabled = 1, #endif #ifdef CONFIG_LOCKDEP .lockdep_depth = 0, /* no locks held yet */ .curr_chain_key = INITIAL_CHAIN_KEY, .lockdep_recursion = 0, #endif #ifdef CONFIG_FUNCTION_GRAPH_TRACER .ret_stack = NULL, .tracing_graph_pause = ATOMIC_INIT(0), #endif #if defined(CONFIG_TRACING) && defined(CONFIG_PREEMPTION) .trace_recursion = 0, #endif #ifdef CONFIG_LIVEPATCH .patch_state = KLP_UNDEFINED, #endif #ifdef CONFIG_SECURITY .security = NULL, #endif #ifdef CONFIG_SECCOMP_FILTER .seccomp = { .filter_count = ATOMIC_INIT(0) }, #endif }; EXPORT_SYMBOL(init_task); |
2.2 什么时候开始有进程的概念?
从Linux的第一行汇编开始,实际这时候是无进程概念的,这时候你不能通过current获取到一个有效的task_struct结构,(虽然current有值,但是这个值并不代表一个task_struct结构),那么什么时候开始有进程的概念的呢?也就是什么时候才能通过current获取到一个有效的task_struct结构的呢?
2.2.1 current指针 - arm64中对应sp_el0
为了搞明白这个问题,我们首先要了解current,下面我们以arm64为例,arm64中的current实际就是sp_el0寄存器中的值,实现如下
W:\opensource\linux-5.10.61\arch\arm64\include\asm\current.h
|
/* * We don't use read_sysreg() as we want the compiler to cache the value where * possible. */ static __always_inline struct task_struct *get_current(void) { unsigned long sp_el0;
asm ("mrs %0, sp_el0" : "=r" (sp_el0));
return (struct task_struct *)sp_el0; }
#define current |
2.2.2 __primary_switched - arm64设置sp_el0,current生效,进入0号进程上下文
什么时候开始有线程的概念?问题就转化为:内核启动的时候,最开始初始化sp_el0的地方在哪呢?
由下面的代码可知,内核在启动过程很靠前的位置,就将sp_el0设置为init_task,在这之后再使用current就能够获取到一个有效的task_struct结构,也就是这个静态的init_task,也就是从这里开始,就有了进程的概念
这个时候对应的进程为init_task,其comm名为swapper,从这里我们能看出,init_task试图将"从最早的汇编代码一直到后面的start_kernel的初始化"都纳入到init_task进程上下文中。
因为init_task的pid为0,所以此时是在0号上下文,需要注意的是,此时的init_task还不是cpu0的idle线程
调用路径:_head -> primary_entry -> __primary_switch -> __primary_switched
文件位置:W:\opensource\linux-5.10.61\arch\arm64\kernel\head.S
|
/* * The following fragment of code is executed with the MMU enabled. * * x0 = __PHYS_OFFSET */ SYM_FUNC_START_LOCAL(__primary_switched) adrp x4, init_thread_union add sp, x4, #THREAD_SIZE adr_l x5, init_task //就是在这里设置current,此后在0号进程上下文 msr sp_el0, x5 // Save thread_info
#ifdef CONFIG_ARM64_PTR_AUTH __ptrauth_keys_init_cpu x5, x6, x7, x8 #endif
adr_l x8, vectors // load VBAR_EL1 with virtual msr vbar_el1, x8 // vector table address isb
stp xzr, x30, [sp, #-16]! mov x29, sp
#ifdef CONFIG_SHADOW_CALL_STACK adr_l scs_sp, init_shadow_call_stack // Set shadow call stack #endif
str_l x21, __fdt_pointer, x5 // Save FDT pointer
ldr_l x4, kimage_vaddr // Save the offset between sub x4, x4, x0 // the kernel virtual and str_l x4, kimage_voffset, x5 // physical mappings
// Clear BSS adr_l x0, __bss_start mov x1, xzr adr_l x2, __bss_stop sub x2, x2, x0 bl __pi_memset dsb ishst // Make zero page visible to PTW
#ifdef CONFIG_KASAN bl kasan_early_init #endif #ifdef CONFIG_RANDOMIZE_BASE tst x23, ~(MIN_KIMG_ALIGN - 1) // already running randomized? b.ne 0f mov x0, x21 // pass FDT address in x0 bl kaslr_early_init // parse FDT for KASLR options cbz x0, 0f // KASLR disabled? just proceed orr x23, x23, x0 // record KASLR offset ldp x29, x30, [sp], #16 // we must enable KASLR, return ret // to __primary_switch() 0: #endif add sp, sp, #16 mov x29, #0 mov x30, #0 b start_kernel //进入start_kernel SYM_FUNC_END(__primary_switched) |
2.3 在sched_init中为cpu0创建0号进程idle
cpu0和其他次cpu的0号进程idle的创建是不一样的,下面我们首先看一下cpu0的idle是怎么创建的
2.3.1 sched_init
代码路径:
|
start_kernel -> sched_init -> init_idle //cpu0创建idle线程 | +-> arch_call_rest_init -> rest_init -> kernel_init //其他cpu创建idle线程 |
需要注意的值,下面在执行sched_init的时候,实际上是在init_task的上下文中,init_task的pid为0,comm名为swapper,此时使用current获取到的也是init_task的线程描述符,但是此时init_task还不属于任何调度类,直到在调用init_idle的时候,才将current的调度类设置为idle_sched_class,这时候init_task才真正的转化为cpu0的idle线程
|
void __init sched_init(void) { ... /* * Make us the idle thread. Technically, schedule() should not be * called from this thread, however somewhere below it might be, * but because we are the idle thread, we just pick up running again * when this runqueue becomes "idle". */ //此处需要注意下面几点 //a) 当前在init_task的上下文,current获取到的是init_task的进程描述符 //b) 在调用init_idle之前,init_task的pid为0,comm名为swapper,不属于任何调度类 //c) 在调用init_idle之后,init_task的pid为0,comm名为swapper/0, // 隶属于idle_sched_class调度类 //在调用init_idle之后,init_task就转化为cpu0的idle线程了 idle_loop init_idle(current, smp_processor_id()); ... } |
2.3.2 init_idle - 为指定的cpu指定idle线程,名为swapper/N
该函数主要完成下面三个工作:
a) 对idle(对于cpu0就是init_task)指向的task_struct结构进行进一步的初始化
b) 指定idle所属的调度类为idle_sched_class
c) 指定idle的comm名为swapper/N
此后init_task就转化为cpu0的idle线程
|
/** * init_idle - set up an idle thread for a given CPU * @idle: task in question * @cpu: CPU the idle task belongs to * * NOTE: this function does not set the idle thread's NEED_RESCHED * flag, to make booting more robust. */ void __init init_idle( struct task_struct *idle, //指向idle线程,实际指向静态的init_task int cpu) //为哪个cpu创建idle { struct rq *rq = cpu_rq(cpu); unsigned long flags;
//1.为这新创建的线程idle,完成调度器相关的初始化 // 对于cpu0,idle是那个静态的init_task结构 // 对于其他cpu,idle是从current(也就是cpu0的idle)刚fork出来的一个新线程 __sched_fork(0, idle);
raw_spin_lock_irqsave(&idle->pi_lock, flags); raw_spin_lock(&rq->lock);
//2.标记线程的状态,和开始运行的时间戳 idle->state = TASK_RUNNING; idle->se.exec_start = sched_clock();
//3.在is_idle_task中通过该标记判断一个线程是不是idle线程 idle->flags |= PF_IDLE;
scs_task_reset(idle); kasan_unpoison_task_stack(idle);
#ifdef CONFIG_SMP /* * Its possible that init_idle() gets called multiple times on a task, * in that case do_set_cpus_allowed() will not do the right thing. * * And since this is boot we can forgo the serialization. */ //4.设置cpumask,注意,这个新创建的idle线程只允许运行在指定的cpu上 // 每个cpu都有自己的idle线程,但是他们的pid和tgid都是0 set_cpus_allowed_common(idle, cpumask_of(cpu)); #endif /* * We're having a chicken and egg problem, even though we are * holding rq->lock, the CPU isn't yet set to this CPU so the * lockdep check in task_group() will fail. * * Similar case to sched_fork(). / Alternatively we could * use task_rq_lock() here and obtain the other rq->lock. * * Silence PROVE_RCU */ //5.设置task->cpu,也就是记录这个idle线程在哪个cpu上运行 rcu_read_lock(); __set_task_cpu(idle, cpu); rcu_read_unlock();
//5.将这个idle线程标记为正在运行,但是这时候还并没有正在的运行起来 rq->idle = idle; rcu_assign_pointer(rq->curr, idle); idle->on_rq = TASK_ON_RQ_QUEUED; #ifdef CONFIG_SMP idle->on_cpu = 1; #endif raw_spin_unlock(&rq->lock); raw_spin_unlock_irqrestore(&idle->pi_lock, flags);
/* Set the preempt count _outside_ the spinlocks! */ init_idle_preempt_count(idle, cpu);
/* * The idle tasks have their own, simple scheduling class: */ //6.初始化idle线程所属的调度类 idle->sched_class = &idle_sched_class; ftrace_graph_init_idle_task(idle, cpu); vtime_init_idle(idle, cpu); #ifdef CONFIG_SMP //7.idle线程的名称为swapperN,其中N为cpu号 // 其中:#define INIT_TASK_COMM "swapper" sprintf(idle->comm, "%s/%d", INIT_TASK_COMM, cpu); #endif } |
2.4 创建1号和2号线程
因为其他次cpu的idle线程是在1号线程kernel_init中创建的,所以在介绍为其他cpu创建idle之前,我们先来看一下1号和2号线程的创建过程
注意:在执行下面函数的时候,已经是在cpu0的0号线程idle的上下文中了
2.4.1 rest_init - 创建1号和2号线程
调用路径:
|
start_kernel -> sched_init -> init_idle //cpu0创建idle线程
|
rest_init依次完成下面工作:
a) 创建1号kernel_init线程
b) 创建2号kthreadd线程
c) 调度1号进程kernel_init执行,在kernel_init中完成对次cpu的idle的创建
d) cpu0进入idle loop
|
noinline void __ref rest_init(void) { int pid; ...
//1.下面开始创建1号和2号线程 // 注意,当前是在cpu0的0号线程idle的上下文中
/* * We need to spawn init first so that it obtains pid 1, however * the init task will end up wanting to create kthreads, which, if * we schedule it before we create kthreadd, will OOPS. */ //2.创建1号线程 // 调用kernel_thread创建1号进程kernel_init,该进程在完成剩下的初始化工作后, // 然后执行execve("/init")调用用户空间的二进制文件,转向用户空间,演变为init进 // 程,(这之后,进程的comm名也变为init),init进程是系统中所有有空间进程的祖先
// 我们在这里发现一个问题,init进程应该是一个用户空间的进程,但是这里却是通过 // kernel_thread的方式创建的,哪init不应该是一个永远运行在内核态的内核线程么? // 它是怎么演变为真正意义上用户空间的init进程的? // 实际上,1号kernel_init进程完成linux的各项配置(包括启动AP)后,就会在根目录、 // /sbin、/etc、/bin等路径下寻找init程序来运行。该init程序会替换kernel_init // 进程(注意:并不是创建一个新的进程来运行init程序,而是一次变身,使用sys_execve // 函数改变核心进程的正文段,将核心进程kernel_init转换成用户进程init),此时处于 // 内核态的1号kernel_init进程将会转换为用户空间内的1号进程init。用户进程init将 // 根据/etc/inittab中提供的信息,完成应用程序的初始化调用。然后init进程会执行 // /bin/sh产生shell界面提供给用户来与Linux系统进行交互
//注意: // kernel_thread创建的新的线程new_task,默认new_task和current的comm是一样的, // 这是因为kernel_thread中实际是调用了copy_process对current进行了复制,这也是为 // 什么下面在创建2号线程kthreadd时,在kthreadd函数刚开始就立刻调用set_task_comm // 重新设置task的comm的原因 pid = kernel_thread(kernel_init, NULL, CLONE_FS); ...
//3.创建2号线程,通过打印发现返回的pid为2 // 它的任务就是管理和调度其他内核线程kernel_thread,他会循环执行一个kthreadd的函数, // 该函数的作用就是运行kthread_create_list全局链表中维护的kthread,当我们调用 // kernel_thread创建的内核线程会被加入到此链表中,因此所有的内核线程都是直接或者间接 // 的以kthreadd为父进程 pid = kernel_thread(kthreadd, NULL, CLONE_FS | CLONE_FILES); ...
/* * The boot idle thread must execute schedule() * at least once to get things moving: */ //4.在schedule_preempt_disabled中调用schedule函数切换当前进程,也就是从0号 // 线程切换出去了,在调用该函数之前,Linux系统中只有三个进程,即0号进程init_task、 // 1号进程kernel_init、2号线程kthreadd,调用该函数后,1号进程kernel_init将会 // 运行!在kernel_init中完成对其他cpu的idle线程的设置 schedule_preempt_disabled();
/* Call into cpu_idle with preempt disabled */ //5.在cpu_startup_entry中,调用do_idle(),0号线程进入idle函数的循环 cpu_startup_entry(CPUHP_ONLINE); } |
2.4.2 kernel_init - 1号进程执行用户空间的程序
|
static int __ref kernel_init(void *unused) { int ret;
//1.在该函数中为其他cpu创建idle线程 kernel_init_freeable();
//2.下面1号线程将会调用用户空间的二进制文件,此后1号线程将从内核态转为用户态线程 //2.1 默认执行ramdisk_execute_command指向的用户空间的二进制文件 if (ramdisk_execute_command) { ret = run_init_process(ramdisk_execute_command); if (!ret) return 0; pr_err("Failed to execute %s (error %d)\n", ramdisk_execute_command, ret); }
/* * We try each of these until one succeeds. * * The Bourne shell can be used instead of init if we are * trying to recover a really broken machine. */ //2.2 如果上面执行失败,则执行execute_command指向的用户空间的二进制文件 if (execute_command) { ret = run_init_process(execute_command); if (!ret) return 0; panic("Requested init %s failed (error %d).", execute_command, ret); }
//2.3 若上面执行失败,则执行CONFIG_DEFAULT_INIT指向的用户空间的二进制文件 if (CONFIG_DEFAULT_INIT[0] != '\0') { ret = run_init_process(CONFIG_DEFAULT_INIT); if (ret) pr_err("Default init %s failed (error %d)\n", CONFIG_DEFAULT_INIT, ret); else return 0; }
//2.4 若上面依然失败,则尝试执行下面的二进制文件 if (!try_to_run_init_process("/sbin/init") || !try_to_run_init_process("/etc/init") || !try_to_run_init_process("/bin/init") || !try_to_run_init_process("/bin/sh")) return 0;
//2.5 捏马,全部都失败了,没救了 panic("No working init found. Try passing init= option to kernel. " "See Linux Documentation/admin-guide/init.rst for guidance."); } |
2.4.2.1 ramdisk_execute_command - 1号线程
其中ramdisk_execute_command定义如下,也就是1号线程要执行的二进制文件,也就是用户空间的二进制文件,该二进制文件默认为根目录下的init文件,但是可用通过cmdline传递的rdinit参数来修改
|
static char *ramdisk_execute_command = "/init"; |

下面解析命令行传入的参数
|
static int __init rdinit_setup(char *str) { unsigned int i;
ramdisk_execute_command = str; /* See "auto" comment in init_setup */ for (i = 1; i < MAX_INIT_ARGS; i++) argv_init[i] = NULL; return 1; } __setup("rdinit=", rdinit_setup); |
2.4.2.2 execute_command - 备用1号线程
execute_command为备用的1号线程,定义如下,通过cmdline中的init参数指定
|
static char *execute_command; |
命令行解析如下
|
static int __init init_setup(char *str) { unsigned int i;
execute_command = str; /* * In case LILO is going to boot us with default command line, * it prepends "auto" before the whole cmdline which makes * the shell think it should execute a script with such name. * So we ignore all arguments entered _before_ init=... [MJ] */ for (i = 1; i < MAX_INIT_ARGS; i++) argv_init[i] = NULL; return 1; } __setup("init=", init_setup); |
2.4.2.3 其他备用1号线程
其他备用的1号线程为:
-
CONFIG_DEFAULT_INIT
-
/sbin/init
-
/etc/init
-
/bin/init
-
/bin/sh
2.4.3 kthreadd - 2号进程完成的工作
2号线程不是本文的重点,简单看一下
|
int kthreadd(void *unused) { struct task_struct *tsk = current;
/* Setup a clean context for our children to inherit. */ //1.进来就改名,要不comm名还是cpu0的idle线程的comm名,即swapper/0 set_task_comm(tsk, "kthreadd"); ignore_signals(tsk); set_cpus_allowed_ptr(tsk, housekeeping_cpumask(HK_FLAG_KTHREAD)); set_mems_allowed(node_states[N_MEMORY]);
current->flags |= PF_NOFREEZE; cgroup_init_kthreadd();
for (;;) { set_current_state(TASK_INTERRUPTIBLE); if (list_empty(&kthread_create_list)) schedule(); __set_current_state(TASK_RUNNING);
spin_lock(&kthread_create_lock);
//2.遍历链表,处理内核线程 while (!list_empty(&kthread_create_list)) { struct kthread_create_info *create;
create = list_entry(kthread_create_list.next, struct kthread_create_info, list); list_del_init(&create->list); spin_unlock(&kthread_create_lock);
create_kthread(create);
spin_lock(&kthread_create_lock); } spin_unlock(&kthread_create_lock); }
return 0; } |
2.5 在1号线程中为其他次cpu创建idle线程
调用路径:
start_kernel -> arch_call_rest_init -> rest_init -> kernel_init -> kernel_init_freeable -> smp_init -> idle_threads_init -> idle_init -> fork_idle -> init_idle
注意:执行下面函数时,是位于1号线程kernel_init的上下文,此时的current为kernel_init
2.5.1 idle_threads_init - 为每个cpu(除了cpu0)创建idle线程
|
/** * idle_threads_init - Initialize idle threads for all cpus */ void __init idle_threads_init(void) { unsigned int cpu, boot_cpu;
//1.此时获取到的还是启动的那个cpu,也就是cpu0 boot_cpu = smp_processor_id();
//2.为其他cpu创建idle线程,因为cpu0的idle线程是单独创建的 // 注意,此时是在1号线程的上下文,而不是0号线程 for_each_possible_cpu(cpu) { if (cpu != boot_cpu) idle_init(cpu); } } |
2.5.2 idle_init - 为指定的cpu创建idle线程
|
/** * idle_init - Initialize the idle thread for a cpu * @cpu: The cpu for which the idle thread should be initialized * * Creates the thread if it does not exist. */ static inline void idle_init(unsigned int cpu) { struct task_struct *tsk = per_cpu(idle_threads, cpu);
if (!tsk) { //1.如果这个cpu上的idle线程还没有创建的话,则创建idle线程 tsk = fork_idle(cpu);
//2.创建成功后赋值给idle_threads全局变量 if (IS_ERR(tsk)) pr_err("SMP: fork_idle() failed for CPU %u\n", cpu); else per_cpu(idle_threads, cpu) = tsk; } } |
2.5.2.1 idle_threads - percpu变量,每个cpu都有自己的idle线程
|
/* * For the hotplug case we keep the task structs around and reuse * them. */ static DEFINE_PER_CPU(struct task_struct *, idle_threads); |
2.5.3 fork_idle - 从current fork出一个线程
|
struct task_struct * __init fork_idle(int cpu) { struct task_struct *task; struct kernel_clone_args args = { .flags = CLONE_VM, };
//1.copy_process函数的功能: // 从current赋值出一个一毛一样的新线程,但是未启动,它会复制寄存器中的值、所有 // 与进程环境相关的部分,新创建的task的comm为swapper/0,pid=0,(因为在调用 // copy_process的时候,指定pid为init_struct_pid,新创建的task的pid为0) // 注意: // 此时current是在1号线程上下文,也就是说其他cpu的idle线程,实际上是从1号 // 线程拷贝过来的,此时的current->pid为1,但是current->comm为swapper/0; task = copy_process(&init_struct_pid, 0, cpu_to_node(cpu), &args); if (!IS_ERR(task)) { //2.设置idle线程的在各个名空间下的pid为0, // 注意:idle线程的pid和tgid都是0 init_idle_pids(task);
//3.将这个task指定为cpu的idle线程,这里会修改上面新创建的task的comm为swapper/N init_idle(task, cpu); }
return task; } |
2.5.3.1 init_struct_pid - 0号idle线程的pid
init_struct_pid如下,也就是是idle线程的pid,也就是0
|
struct pid init_struct_pid = { .count = REFCOUNT_INIT(1), .tasks = { { .first = NULL }, { .first = NULL }, { .first = NULL }, }, .level = 0, .numbers = { { .nr = 0, //0号线程,idle线程 .ns = &init_pid_ns, //0号线程的名空间 }, } }; |
2.5.3.2 init_pid_ns - 0号进程的pid_namespace
其中:
|
/* * PID-map pages start out as NULL, they get allocated upon * first use and are never deallocated. This way a low pid_max * value does not cause lots of bitmaps to be allocated, but * the scheme scales to up to 4 million PIDs, runtime. */ struct pid_namespace init_pid_ns = { .kref = KREF_INIT(2), .idr = IDR_INIT(init_pid_ns.idr), .pid_allocated = PIDNS_ADDING, .level = 0, .child_reaper = &init_task, .user_ns = &init_user_ns, .ns.inum = PROC_PID_INIT_INO, #ifdef CONFIG_PID_NS .ns.ops = &pidns_operations, #endif }; |
2.5.4 init_idle_pids - 设置每一个名空间下的idle线程的pid
|
static inline void init_idle_pids(struct task_struct *idle) { enum pid_type type;
//设置每一个名空间下的idle线程的pid //可见每个名空间下的idle线程的pid都是0 for (type = PIDTYPE_PID; type < PIDTYPE_MAX; ++type) { INIT_HLIST_NODE(&idle->pid_links[type]); /* not really needed */ init_task_pid(idle, type, &init_struct_pid); } } |
三、idle线程要完成的工作
由上面的分析可知,cpu0和其他cpu的idle线程创建位置是不一样的,理论上,创建idle时所处的进程上下文current是什么,创建出来的idle就应该执行相应的后续流程,但是真的是这样吗???
3.1 为什么是cpu_startup_entry
通过打印发现,所有cpu的idle都会进入cpu_startup_entry接口,为什么呢???
-
cpu0
由上面的分析可知,cpu0的idle是延续init_task的执行流程,这个好理解。所以cpu0的idle完成的工作,应该和正常的内核启动流程一致。如下,内核初启动后期会调用到rest_init,rest_init是内核最后一个调用的函数,接着便进入cpu_startup_entry
|
start_kernel -> arch_call_rest_init -> rest_init -> cpu_startup_entry |
-
其他次cpu
而其他cpu的进入idle是在这些cpu被唤醒之后,次cpu的唤醒流程如下:
|
secondary_entry -> secondary_startup -> __secondary_switched -> secondary_start_kernel -> cpu_startup_entry |
cpu_startup_entry又是怎么和上面创建的idle线程对应的task_struct结构关联到一起的呢?或者说上面的其他cpu被唤醒后的执行路径是什么时候被标记为idle的进程上下文的呢?
实际上,次cpu在__secondary_switched期间被标记为进程上下文,此时所处的进程上下文正是上面创建的idle线程,但是为什么呢?
次cpu刚被唤醒时,从指定的汇编代码处开始执行第一条汇编指令,实际上此时也是没有线程的概念的,那么我们在前面为次cpu创建的idle线程,是在什么时候和这个cpu关联起来的呢?
带着种种疑问,我们看一下cpu0唤醒其他次cpu的流程,描述如下:
a) [cpu0] 执行bringup_cpu,由cpu0主动唤醒其他次cpu,我们假设这个cpu为cpuN
b) [cpu0] 执行__cpu_up,在唤醒cpuN之前,我们需要将上面为cpuN创建的idle线程的相关信息,记录在全局变量secondary_data中
c) [cpu0] 发送事件或者中断信号,唤醒cpuN
d) [cpuN] cpuN被唤醒后,从secondary_entry汇编代码处开始执行
e) [cpuN] 当cpuN的启动流程进入到__secondary_switched时,会从secondary_data中读取"之前为这个cpu创建的idle线程"信息,并赋值给sp_el0,此后current就指向了"之前为这个cpu创建的idle线程",换句话说,在这之后,这个cpuN的idle线程就是启动流程之后的代码了,如下
|
secondary_entry -> secondary_startup -> __secondary_switched -> secondary_start_kernel -> cpu_startup_entry |
下面我们就来一探究竟,我们从次cpu的唤醒流程入手开始分析
3.1.1 bringup_cpu - cpu0设置"次cpu被唤醒后的current"
在SMP多核启动过程中,在内核启动后期,cpu0需要唤醒其他次cpu,代码执行流程如下,值得注意的是:下面的代码流程还是在cpu0上运行的,是cpu0主动去唤醒其他次cpu
|
kernel_init -> kernel_init_freeable -> smp_init -> bringup_nonboot_cpus -> cpu_up -> _cpu_up -> cpuhp_up_callbacks -> cpuhp_invoke_callback -> bringup_cpu -> __cpu_up |
W:\opensource\linux-5.10.61\kernel\cpu.c
|
static int bringup_cpu( unsigned int cpu) //要唤醒哪个cpu { //1.获取这个cpu对应的idle线程,也就是前面在1号线程中为其他cpu创建的idle线程 struct task_struct *idle = idle_thread_get(cpu); int ret;
/* * Some architectures have to walk the irq descriptors to * setup the vector space for the cpu which comes online. * Prevent irq alloc/free across the bringup. */ irq_lock_sparse();
/* Arch-specific enabling code. */ //2.在下面函数中将idle设置给这个指定cpu的current ret = __cpu_up(cpu, idle); irq_unlock_sparse(); if (ret) return ret; return bringup_wait_for_ap(cpu); } |
3.1.2 __cpu_up - cpu0唤醒指定的cpu,并指定这个cpu对应的idle线程
W:\opensource\linux-5.10.61\arch\arm64\kernel\smp.c
|
int __cpu_up( unsigned int cpu, //要唤醒的cpu struct task_struct *idle) //这个cpu对应的idle线程 { int ret; long status;
/* * We need to tell the secondary core where to find its stack and the * page tables. */ //1.在这里将各个cpu的idle线程设置给全局变量secondary_data,后面从该全局变量中获取 secondary_data.task = idle; secondary_data.stack = task_stack_page(idle) + THREAD_SIZE; update_cpu_boot_status(CPU_MMU_OFF); __flush_dcache_area(&secondary_data, sizeof(secondary_data));
//2.下面是cpu的唤醒逻辑 // 次cpu被唤醒后会从secondary_entry处开始运行, // 并在__secondary_switched中设置自己的current /* Now bring the CPU into our world */ ret = boot_secondary(cpu, idle); if (ret) { pr_err("CPU%u: failed to boot: %d\n", cpu, ret); return ret; }
/* * CPU was successfully started, wait for it to come online or * time out. */ //3.等待其他cpu被唤醒,成功唤醒后退出 // 关于SMP多核启动的更多信息,参见本博客其他文章 wait_for_completion_timeout(&cpu_running, msecs_to_jiffies(5000)); if (cpu_online(cpu)) return 0;
//4.代码走到这里表示唤醒失败 pr_crit("CPU%u: failed to come online\n", cpu); secondary_data.task = NULL; secondary_data.stack = NULL; __flush_dcache_area(&secondary_data, sizeof(secondary_data)); status = READ_ONCE(secondary_data.status); if (status == CPU_MMU_OFF) status = READ_ONCE(__early_cpu_boot_status);
switch (status & CPU_BOOT_STATUS_MASK) { default: pr_err("CPU%u: failed in unknown state : 0x%lx\n", cpu, status); cpus_stuck_in_kernel++; break; case CPU_KILL_ME: if (!op_cpu_kill(cpu)) { pr_crit("CPU%u: died during early boot\n", cpu); break; } pr_crit("CPU%u: may not have shut down cleanly\n", cpu); fallthrough; case CPU_STUCK_IN_KERNEL: pr_crit("CPU%u: is stuck in kernel\n", cpu); if (status & CPU_STUCK_REASON_52_BIT_VA) pr_crit("CPU%u: does not support 52-bit VAs\n", cpu); if (status & CPU_STUCK_REASON_NO_GRAN) { pr_crit("CPU%u: does not support %luK granule\n", cpu, PAGE_SIZE / SZ_1K); } cpus_stuck_in_kernel++; break; case CPU_PANIC_KERNEL: panic("CPU%u detected unsupported configuration\n", cpu); }
return -EIO; } |
3.1.3 __secondary_switched - 次cpu被唤醒时在这里设置current
由下面分析可知,其他cpu被唤醒时,从secondary_data.stack中获取到之前为这个cpu创建的idle线程,并赋值给sp_el0,也就是current,此后这些次cpu也便有了线程的概念,(因为可以通过current获取到一个有效的task_struct结构了)。
换句话说,从sp_el0被设置的那一刻其,之后的所有代码都落在了次cpu的idle线程上下文中。即,所有次cpu的idle线程完成的工作,就是从sp_el0被设置的地方之后的所有代码逻辑。之后的流程如下:
secondary_start_kernel -> cpu_startup_entry
所以,其他次cpu在启动完毕后的idle线程最终也会执行到cpu_startup_entry
W:\opensource\linux-5.10.61\arch\arm64\kernel\head.S
|
SYM_FUNC_START_LOCAL(__secondary_switched) adr_l x5, vectors msr vbar_el1, x5 isb
//下面设置current指针后,就已经有进程的概念了 adr_l x0, secondary_data ldr x1, [x0, #CPU_BOOT_STACK] // get secondary_data.stack cbz x1, __secondary_too_slow mov sp, x1 ldr x2, [x0, #CPU_BOOT_TASK] cbz x2, __secondary_too_slow //这里的x2 = secondary_data.stack msr sp_el0, x2 //在这里设置current指针 scs_load x2, x3 mov x29, #0 mov x30, #0
#ifdef CONFIG_ARM64_PTR_AUTH ptrauth_keys_init_cpu x2, x3, x4, x5 #endif
b secondary_start_kernel SYM_FUNC_END(__secondary_switched) |
3.2 cpu_startup_entry - idle线程要完成的工作
需要注意的是:使用cpuidle framework进入idle状态时,本地irq是处于关闭的状态,因此从idle返回时,只能接着往下执行,直到irq被打开,才能执行相应的中断handler,这和之前传统的cpuidle不同。这也是为什么在menu governor中,reflect接口中只是简单的置一个标志。因为reflect是在关中断时被调用的,需要尽快返回,以便处理中断事件。
|
void cpu_startup_entry(enum cpuhp_state state) { //0.笔者增加的调试信息 pr_info("BYHP [%s-%d]: current=%s, pid=%d\n", __func__, __LINE__, current->comm, current->pid);
//1.进入idle前的准备工作,目前开源内核中只有arm32实现 // arm32是关闭的fiq,我们暂不研究 arch_cpu_idle_prepare(); cpuhp_online_idle(state);
//2.cpuidle循环 // 不管是启动阶段还是重新进入idle线程,都是在下面的循环中 // 即使退出idle循环,在下一次重新进入idle的时候,也是在下面的循环中 while (1) do_idle(); } |
上面调试信息打印的日志如下:
|
[ 0.199816] smp: Bringing up secondary CPUs ... [ 0.217495] Detected PIPT I-cache on CPU1 [ 0.220972] BYHP [cpu_startup_entry-350]: current=swapper/0, pid=0 [ 0.221718] GICv3: CPU1: found redistributor 1 region 0:0x00000000080c0000 [ 0.225485] CPU1: Booted secondary processor 0x0000000001 [0x000f0510] [ 0.227460] BYHP [cpu_startup_entry-350]: current=swapper/1, pid=0 [ 0.265071] Detected PIPT I-cache on CPU2 [ 0.265246] GICv3: CPU2: found redistributor 2 region 0:0x00000000080e0000 [ 0.266921] CPU2: Booted secondary processor 0x0000000002 [0x000f0510] [ 0.266961] BYHP [cpu_startup_entry-350]: current=swapper/2, pid=0 [ 0.291141] Detected PIPT I-cache on CPU3 [ 0.291315] GICv3: CPU3: found redistributor 3 region 0:0x0000000008100000 [ 0.291523] CPU3: Booted secondary processor 0x0000000003 [0x000f0510] [ 0.291554] BYHP [cpu_startup_entry-350]: current=swapper/3, pid=0 [ 0.298709] smp: Brought up 1 node, 4 CPUs [ 0.298850] SMP: Total of 4 processors activated. |
3.3 do_idle - idle线程要完成的工作
简单的说,idle要完成的工作就是选择一个idle等级,并进入
U:\linux-5.10.61\kernel\sched\idle.c
|
/* * Generic idle loop implementation * * Called with polling cleared. */ static void do_idle(void) { //0.获取当前cpu的id int cpu = smp_processor_id(); /* * If the arch has a polling bit, we maintain an invariant: * * Our polling bit is clear if we're not scheduled (i.e. if rq->curr != * rq->idle). This means that, if rq->idle has the polling bit set, * then setting need_resched is guaranteed to cause the CPU to * reschedule. */
__current_set_polling(); tick_nohz_idle_enter();
//1.判断系统是否需要调度,如果不需要调度就会一直在这个循环里面, // 实际上并不是一直循环,而是睡眠了 while (!need_resched()) { rmb();
//2.特别注意,在idle期间关闭这个cpu的中断,因此下面从idle返回时, // 只能接着往下执行,直到irq被打开,才能执行相应的中断handler // 因为是在关中断的上下文,所以应该尽快执行完毕,不要做太多事情, // 这也是为什么menu governor在reflect接口中只是简单的置一个标志。 // 因为reflect是在关中断时被调用的,需要尽快返回,以便处理中断事件 local_irq_disable();
if (cpu_is_offline(cpu)) { tick_nohz_idle_stop_tick(); cpuhp_report_idle_dead(); arch_cpu_idle_dead(); }
//3.平台自己实现,为进入idle做一些准备工作, // 例如在arm32上是将arm32的呼吸灯给关闭了 arch_cpu_idle_enter(); rcu_nocb_flush_deferred_wakeup();
/* * In poll mode we reenable interrupts and spin. Also if we * detected in the wakeup from idle path that the tick * broadcast device expired for us, we don't want to go deep * idle as we know that the IPI is going to arrive right away. */ //4.因为在poll mode中,我们一般会使能中断和自旋锁,或者,如果我们在 // 退出idle的时候发现tick广播设备已经过期,这时候我们将努力避免进 // 入深度睡眠,因为我们知道IPI中断马上就来了 if (cpu_idle_force_poll || tick_check_broadcast_expired()) { tick_nohz_idle_restart_tick(); cpu_idle_poll(); } else { cpuidle_idle_call(); }
//5.代码走到这里,表示已经从idle线程中退出了 // 通过sev或者产生中断的方式,唤醒了这个cpu, // 注意: // 即使中断被关闭,当产生中断的时候,cpu也会被 // 唤醒的,但是不会立刻执行中断服务程序
//6.ARM32上只是将呼吸灯重新打开 arch_cpu_idle_exit(); }
/* * Since we fell out of the loop above, we know TIF_NEED_RESCHED must * be set, propagate it into PREEMPT_NEED_RESCHED. * * This is required because for polling idle loops we will not have had * an IPI to fold the state for us. */ //7.代码走到这里,表示从idle退出时发现需要重新调度,这时候从睡眠中醒过来,向下执行调度逻辑 preempt_set_need_resched(); tick_nohz_idle_exit(); __current_clr_polling();
/* * We promise to call sched_ttwu_pending() and reschedule if * need_resched() is set while polling is set. That means that clearing * polling needs to be visible before doing these things. */ smp_mb__after_atomic();
/* * RCU relies on this call to be done outside of an RCU read-side * critical section. */ flush_smp_call_function_from_idle();
//8.这是从idle中开始调度吗??? schedule_idle();
if (unlikely(klp_patch_pending(current))) klp_update_patch_state(current); } |
3.3.1 arch_cpu_idle_enter - 进idle的一些准备工作,平台相关
U:\linux-5.10.61\arch\arm\kernel\process.c
|
void arch_cpu_idle_enter(void) { //呼吸灯打开 ledtrig_cpu(CPU_LED_IDLE_START); #ifdef CONFIG_PL310_ERRATA_769419 wmb(); #endif } |
3.3.2 arch_cpu_idle_exit - 退出idle时的一些恢复工作,平台相关
U:\linux-5.10.61\arch\arm\kernel\process.c
|
void arch_cpu_idle_exit(void) { //呼吸灯关闭 ledtrig_cpu(CPU_LED_IDLE_END); } |
3.4 cpu_idle_poll - 执行cpu_relax,进入浅睡眠
在poll mode下,调用该函数进入idle睡眠状态,该函数调用的cpu_relax实际上只是一条"暗示指令",也就是说这种idle实际上是忙等
|
static noinline int __cpuidle cpu_idle_poll(void) { //1.打印trace信息,注意忙等时的C state为0 trace_cpu_idle(0, smp_processor_id());
stop_critical_timings(); rcu_idle_enter(); local_irq_enable();
//2.进入睡眠,这里实际就是个死循环,cpu实际上并没有睡死 while (!tif_need_resched() && (cpu_idle_force_poll || tick_check_broadcast_expired())) cpu_relax();
//3.代码走到这里表示从睡眠中退出了 rcu_idle_exit(); start_critical_timings();
//4.退出睡眠,值为-1 trace_cpu_idle(PWR_EVENT_EXIT, smp_processor_id());
return 1; } |
3.4.1 cpu_relax - 忙等
在arm32中实现如下:
U:\linux-5.10.61\arch\arm\include\asm\vdso\processor.h
|
#if __LINUX_ARM_ARCH__ == 6 || defined(CONFIG_ARM_ERRATA_754327) #define cpu_relax() \ do { \ smp_mb(); \ __asm__ __volatile__("nop; nop; nop; nop; nop; nop; nop; nop; nop; nop;"); \ } while (0) #else //除了ARM6和ERRATA_754327平台之外,cpu_relax实际上就是一句barrier #define cpu_relax() barrier() #endif |
在arm64中实现如下:
U:\linux-5.10.61\arch\arm64\include\asm\vdso\processor.h
|
static inline void cpu_relax(void) { asm volatile("yield" ::: "memory"); } |
能够发现:
-
ARM32中,在调用cpu_relax的时候,只有内存屏障
-
ARM64中,在调用cpu_relax的时候,不仅仅有内存屏障还存一个yield指令,yield是让cpu松弛下来,降低功耗,把资源配置给其他硬件thread等
印象中cpu_relax是忙等,但是由上面的cpu_relax实现可知,除了ARM6和ERRATA_754327外,cpu_relax实际就是barrier,而barrier是避免gcc对code的优化,(也就是说是在编译过程中才有效的指令,没有实际的机器码),保证每次去内存读取对应的值,这和忙等待有啥关系呢?
的确,cpu_relax是用于busy loop的场景,代码示例如下:
|
flag = 0; while (flag == 0) { cpu_relax(); } |
程序逻辑很奇怪,当然它实际上是期待其他的thread(这里说的thread是操作系统中软件线程的概念)会修改flag这个全局变量,从而解除本cpu的忙等待状态。
cpu_relax必须具备两个功能:
-
确保对flag的访问每次都从memory中加载,也就是barrier()函数的作用
-
通知底层CPU,目前代码没有在做什么实际有意义的事情,如果可以的话,别让cpu做太多事情,系统的资源尽量让给其他的cpu,(当前硬件thread没有太多的事情要做,可以他core的资源让给同一个core下的其他硬件thread)
当然,由于ARMv8之前的CPU不支持上面的第二个功能,因此你看到的cpu_relax就是barrier。如果有兴趣看看ARM64的代码,你会有新的发现:
|
static inline void cpu_relax(void) { asm volatile("yield" ::: "memory"); } |
在这里,嵌入式汇编中的clobber list没有描述汇编代码对寄存器的修改情况,只是有一个memory的标记。我们知道,clober list是gcc和gas的接口,用于gas通知gcc它对寄存器和memory的修改情况。因此,这里的memory关键字就是告知gcc,在汇编代码中,我修改了memory中的内容,cpu_relax之前的c代码块和cpu_relax之后的c代码块看到的memory是不一样的,对memory的访问不能依赖于嵌入式汇编之前的c代码块中寄存器的内容,需要重新加载,这也就是Optimization barrier的功能。
而上面汇编中的yield指令则完成了cpu_relax的第二个功能,即让CPU松弛下来,降低功耗,把资源配置给其他硬件thread等。
3.4.2 yield指令
参考资料:
https://blog.csdn.net/lsshao/article/details/116739421
https://developer.arm.com/documentation/dui0802/b/A32-and-T32-Instructions/SEV--SEVL--WFE--WFI--and-YIELD
首先我们需要搞明白两个基本概念:
-
暗示指令(hint instructions)
是指对于程序运行结果的正确性没有影响,而是出于对性能或者功耗等因素的考虑,软件对CPU给出的一种指示,CPU硬件基于这种指示进行相关策略调整,当然CPU也可以直接忽略这种指示,类似nop处理方式。
-
多核多线
例如有一个工具厂,引进了四条加工流水线,每一个流水线上两班工人轮流。这个工厂有点特殊:相同流水线上轮流的两班工人,生产各自的工具,例如一班生产斧子,另一班生产榔头。如果把工厂比作CPU,流水线就类似处理核,即core,一班工人就是处理线程,即硬件thread
那么上述就是一个4核2线的CPU,从操作系统层面看有8个逻辑CPU,(一个硬件thread就是一个逻辑cpu)
这里我们关注多线:两个逻辑CPU实际上分时共享一个物理CPU核,由硬件决定究竟哪个逻辑CPU使用物理CPU核。
yield指令就是一个暗示指令,即通知CPU硬件:我暂时没有正事,你可以让我这个逻辑CPU让出物理CPU核。对于没有支持多线的平台,yield指令简单实现为nop
ARM官方文档对yield指令的解释如下,下面说的thread就是硬件线程,可见这个只在多线程中是有效的
These are hint instructions. It is optional whether they are implemented or not. If any one of them is not implemented, it executes as a NOP. The assembler produces a diagnostic message if the instruction executes as a NOP on the target.
YIELD indicates to the hardware that the current thread is performing a task, for example a spinlock, that can be swapped out. Hardware can use this hint to suspend and resume threads in a multithreading system.
3.5 cpuidle_idle_call - 选择一个C state进入睡眠,可能会进入深睡眠
关于本函数使用的下面接口,我们此处先只了解接口的功能,详细逻辑,我们在后续的文章中介绍
-
cpuidle_find_deepest_state : 直接选择睡眠最深的C state
-
cpuidle_select : 根据系统的状况,选择一个合适的C state
-
call_cpuidle : 进入指定等级的C state
-
cpuidle_reflect : 从idle中退出时,通知cpuidle governor更新状态
|
/** * cpuidle_idle_call - the main idle function * * NOTE: no locks or semaphores should be used here * * On archs that support TIF_POLLING_NRFLAG, is called with polling * set, and it returns with polling set. If it ever stops polling, it * must clear the polling bit. */ static void cpuidle_idle_call(void) { struct cpuidle_device *dev = cpuidle_get_device(); struct cpuidle_driver *drv = cpuidle_get_cpu_driver(dev); int next_state, entered_state;
/* * Check if the idle task must be rescheduled. If it is the * case, exit the function after re-enabling the local irq. */ //1.如果需要调度,就不需要睡眠了 if (need_resched()) { local_irq_enable(); return; }
/* * The RCU framework needs to be told that we are entering an idle * section, so no more rcu read side critical sections and one more * step to the grace period */ //2.如果当前cpuidle子系统不可用,也就是说不能通过cpuidle子系统去选择idle等级 // 则执行下面的逻辑,暂不分析 if (cpuidle_not_available(drv, dev)) { tick_nohz_idle_stop_tick();
//2.1 进入idle,这里不需要选idle等级,arm64执行wfi进入睡眠 default_idle_call(); goto exit_idle; }
/* * Suspend-to-idle ("s2idle") is a system state in which all user space * has been frozen, all I/O devices have been suspended and the only * activity happens here and in interrupts (if any). In that case bypass * the cpuidle governor and go stratight for the deepest idle state * available. Possibly also suspend the local tick and the entire * timekeeping to prevent timer interrupts from kicking us out of idle * until a proper wakeup interrupt happens. */ //3.由上面的注释可知: // Suspend-to-idle(s2idle)是一种系统状态,在这种状态下,所有用户空间都被冻结了, // 所有I/O设备都被挂起了,唯一的活动就是这里和中断(如果有中断的话)。在这种情况 // 下,bypass掉cpuidle子系统,直接进入最深的睡眠状态 // dev->forced_idle_latency_limit_ns表示:为了防止timer中断打断我们的睡眠状态, // 可能会将local tick和整个timerkeeping子系统关闭,直到一个合适的唤醒中断发生 if (idle_should_enter_s2idle() || dev->forced_idle_latency_limit_ns) { u64 max_latency_ns;
if (idle_should_enter_s2idle()) {
entered_state = call_cpuidle_s2idle(drv, dev); if (entered_state > 0) goto exit_idle;
max_latency_ns = U64_MAX; } else { max_latency_ns = dev->forced_idle_latency_limit_ns; }
tick_nohz_idle_stop_tick();
//3.1 直接进入最深的睡眠状态 next_state = cpuidle_find_deepest_state(drv, dev, max_latency_ns); call_cpuidle(drv, dev, next_state); } else { bool stop_tick = true;
/* * Ask the cpuidle framework to choose a convenient idle state. */ //4.下面需要根据系统的状态,选择一个C state next_state = cpuidle_select(drv, dev, &stop_tick);
//4.1 根据上面返回的stop_tick,判断在该C state下是否需要关闭tick if (stop_tick || tick_nohz_tick_stopped()) tick_nohz_idle_stop_tick(); else tick_nohz_idle_retain_tick();
//4.2 进入上面选择好的idle等级 entered_state = call_cpuidle(drv, dev, next_state);
/* * Give the governor an opportunity to reflect on the outcome */ //5.代码走到这,表示已经从idle中退出了 // 调用cpuidle_reflect通知cpuidle governor更新状态 // 在cpuidle_reflect中实际仅仅是设置一个标记,因为现在是在关中断上下文, // 不能做太多的事情,需要尽快完成以便尽快使能中断,处理中断服务函数 cpuidle_reflect(dev, entered_state); }
exit_idle: __current_set_polling();
/* * It is up to the idle functions to reenable local interrupts */ //6.注意,在这里才重新使能中断,在这之后才能响应中断 if (WARN_ON_ONCE(irqs_disabled())) local_irq_enable(); } |
3.5.1 default_idle_call - 当不能通过cpuidle子系统选择C state时,走该逻辑进入idle
|
/** * default_idle_call - Default CPU idle routine. * * To use when the cpuidle framework cannot be used. */ void __cpuidle default_idle_call(void) { if (current_clr_polling_and_test()) { //1.如果当前系统需要调度,就不进入idle了,打开中断后就退出了 local_irq_enable(); } else {
//2.trace相关,注意,wfi实际对应的是idx为1 trace_cpu_idle(1, smp_processor_id()); stop_critical_timings();
/* * arch_cpu_idle() is supposed to enable IRQs, however * we can't do that because of RCU and tracing. * * Trace IRQs enable here, then switch off RCU, and have * arch_cpu_idle() use raw_local_irq_enable(). Note that * rcu_idle_enter() relies on lockdep IRQ state, so switch that * last -- this is very similar to the entry code. */ trace_hardirqs_on_prepare(); lockdep_hardirqs_on_prepare(_THIS_IP_); rcu_idle_enter(); lockdep_hardirqs_on(_THIS_IP_);
//由平台自己定义idle arch_cpu_idle();
/* * OK, so IRQs are enabled here, but RCU needs them disabled to * turn itself back on.. funny thing is that disabling IRQs * will cause tracing, which needs RCU. Jump through hoops to * make it 'work'. */ raw_local_irq_disable(); lockdep_hardirqs_off(_THIS_IP_); rcu_idle_exit(); lockdep_hardirqs_on(_THIS_IP_); raw_local_irq_enable();
start_critical_timings(); trace_cpu_idle(PWR_EVENT_EXIT, smp_processor_id()); } } |
3.5.2 arch_cpu_idle - arm64,执行wfi进入睡眠
W:\opensource\linux-5.10.61\arch\arm64\kernel\process.c
|
/* * This is our default idle handler. */ void noinstr arch_cpu_idle(void) { /* * This should do all the clock switching and wait for interrupt * tricks */ cpu_do_idle(); raw_local_irq_enable(); } |
3.5.3 cpu_do_idle - 进入等级为0的idle状态,由平台自己实现
arm64实现如下,执行wfi指令进入idle状态
W:\opensource\linux-5.10.61\arch\arm64\kernel\process.c
|
/* * cpu_do_idle() * * Idle the processor (wait for interrupt). * * If the CPU supports priority masking we must do additional work to * ensure that interrupts are not masked at the PMR (because the core will * not wake up if we block the wake up signal in the interrupt controller). */ void noinstr cpu_do_idle(void) { if (system_uses_irq_prio_masking()) __cpu_do_idle_irqprio(); else __cpu_do_idle(); } |
3.5.4 __cpu_do_idle_irqprio
|
static void noinstr __cpu_do_idle_irqprio(void) { unsigned long pmr; unsigned long daif_bits;
//1.这是在干啥??? daif_bits = read_sysreg(daif); write_sysreg(daif_bits | PSR_I_BIT, daif);
/* * Unmask PMR before going idle to make sure interrupts can * be raised. */ pmr = gic_read_pmr(); gic_write_pmr(GIC_PRIO_IRQON | GIC_PRIO_PSR_I_SET);
//2.执行wfi进入睡眠 __cpu_do_idle();
gic_write_pmr(pmr); write_sysreg(daif_bits, daif); } |
3.5.5 __cpu_do_idle - 执行wfi进入睡眠
|
static void noinstr __cpu_do_idle(void) { dsb(sy);
//执行wfi进入睡眠 wfi(); } |
3.6 cpuidle_reflect - cpu退出idle时,通知governor做相关的统计工作
当退出idle的时候,调用该函数,通知governor完成对上一次的睡眠质量进行统计
|
/** * cpuidle_reflect - tell the underlying governor what was the state * we were in * * @dev : the cpuidle device * @index: the index in the idle state table * */ void cpuidle_reflect( struct cpuidle_device *dev, int index) //刚刚是在哪个idle等级 { if (cpuidle_curr_governor->reflect && index >= 0) cpuidle_curr_governor->reflect(dev, index); } |
四、本章涉及函数
4.1 schedule_preempt_disabled - 调用schedule,调度其他线程执行
|
/** * schedule_preempt_disabled - called with preemption disabled * * Returns with preemption disabled. Note: preempt_count must be 1 */ void __sched schedule_preempt_disabled(void) { sched_preempt_enable_no_resched(); schedule(); preempt_disable(); } |
4.2 __sched_fork - 完成调度器相关的初始化
由下面的函数可知,该函数的功能是为这新创建的线程p,完成调度器相关的初始化,p是从current fork出来的线程
|
/* * Perform scheduler related setup for a newly forked process p. * p is forked by current. * * __sched_fork() is basic setup used by init_idle() too: */ static void __sched_fork( unsigned long clone_flags, struct task_struct *p) //从current fork出来的线程 { p->on_rq = 0;
p->se.on_rq = 0; p->se.exec_start = 0; p->se.sum_exec_runtime = 0; p->se.prev_sum_exec_runtime = 0; p->se.nr_migrations = 0; p->se.vruntime = 0; INIT_LIST_HEAD(&p->se.group_node);
#ifdef CONFIG_FAIR_GROUP_SCHED p->se.cfs_rq = NULL; #endif
#ifdef CONFIG_SCHEDSTATS /* Even if schedstat is disabled, there should not be garbage */ memset(&p->se.statistics, 0, sizeof(p->se.statistics)); #endif
RB_CLEAR_NODE(&p->dl.rb_node); init_dl_task_timer(&p->dl); init_dl_inactive_task_timer(&p->dl); __dl_clear_params(p);
INIT_LIST_HEAD(&p->rt.run_list); p->rt.timeout = 0; p->rt.time_slice = sched_rr_timeslice; p->rt.on_rq = 0; p->rt.on_list = 0;
#ifdef CONFIG_PREEMPT_NOTIFIERS INIT_HLIST_HEAD(&p->preempt_notifiers); #endif
#ifdef CONFIG_COMPACTION p->capture_control = NULL; #endif init_numa_balancing(clone_flags, p); #ifdef CONFIG_SMP p->wake_entry.u_flags = CSD_TYPE_TTWU; #endif } |
4.3 copy_process - 从current复制一个线程处理
参考文档:
https://blog.csdn.net/zhoudaxia/article/details/7367044
https://blog.csdn.net/weixin_42250655/article/details/102533048
https://blog.csdn.net/tiankong_/article/details/76420006
copy_process是对current进行克隆,该函数就像老太太的裹脚布,又臭又长
Linux将进程的创建和执行分为2个阶段,第一个阶段是创建,父进程首先复制子进程,所复制出来的子进程拥有自己的任务结构体和系统堆栈,除此之外所有资源都与父进程共享。
Linux提供两种方式复制子进程:一个是fork,另外一个是clone。fork函数复制时将父进程的所有资源都通过复制数据结构进行了复制,然后传递给子进程,所以fork函数不带参数;clone则是将部分父进程的资源的数据结构进行复制,复制哪些资源是可选择的,这个可以通过参数设定,所以clone函数带参数,没有复制的资源可以通过指针共享给子进程,fork可以看出是完全版的clone,而clone克隆的只是fork的一部分
两者的声明如下:
|
pid_t fork(void); int clone(int (*fn)(void *), void *child_stack, int flags, void *arg, ... /* pid_t *ptid, void *newtls, pid_t *ctid */ ); |
fn为函数指针,此指针指向一个函数体,即想要创建进程的静态程序;child_stack为给子进程分配系统堆栈的指针;arg就是传给子进程的参数;flags为要复制资源的标志:
为了提高系统的效率,后来的Linux设计者又增加了一个系统调用vfork。vfork所创建的不是进程而是线程,它所复制的是除了任务结构体和系统堆栈之外的所有资源的数据结构,而任务结构体和系统堆栈是与父进程共用的。
第二个阶段就是所创建进程的执行,子进程创建完后一般都会走自己的路。Linux为了子进程能做自己的事特意提供了一个系统调用execve,用以执行一个可执行程序的映像,这个映像以文件形式存在(这句话其实就是说用execve可以调用一个可执行程序,因为这个可执行程序就在磁盘上,所有是以文件形式存在的,而映像是说已经编译链接好了的,只要调入内存就可以执行,一般为二进制文件)。vfork创建的子进程要先于父进程执行,子进程执行时,父进程处于挂起状态,子进程执行完,唤醒父进程。
下面的clone_flags可取值为:
-
CLONE_FS
子进程与父进程共享相同的文件系统,包括root、当前目录、umask
-
CLONE_FILES : 共享文件描述符表
子进程与父进程共享相同的文件描述符(file descriptor)表,如果指定了CLONE_FILES标志,父、子进程会共享同一个打开文件描述符表,也就是说父子进程指向的文件描述符位于同一个虚拟内存中,这样不管父子进程中谁改变了该文件描述符的性质,对方都会被影响。如果不设置,那么就和fork之后的父子进程的文件描述符状态相同,各自的文件描述符都在各自的虚拟内存中。
-
CLONE_PID
子进程在创建时PID与父进程一致
-
CLONE_SIGHAND : 共享对信号的处置设置
子进程与父进程共享相同的信号处理(signal handler)表
如果设置了CLONE_SIGHAND,那么父子进程将共享同一个信号处置表。和共享同一个文件描述符含义相似,就是父子进程中无论谁使用了sigaction或者signal函数改变对信号的处置,则对方都会被影响。如果未设置就和fork调用后的情况相同。
-
CLONE_VFORK : 挂起父进程直至子进程退出或调用exec()
父进程被挂起,直至子进程释放虚拟内存资源
如果设置了CLONE_VFORK,父进程将一直挂起,直至子进程调用exec()或子进程结束为止
-
CLONE_VM : 共享进程的虚拟内存
子进程与父进程运行于相同的内存空间
如果设置了CLONE_VM标志,父子进程会共享同一个虚拟内存页(如同vfork())。无论哪个进程更新了内存,或是调用了mmap(),munmap(),另一个进程同样会观察到这些变化如果未设置CLONE_VM,就如同fork()。
共享同一虚拟内存是线程的关键属性之一,POSIX线程标准对此也有要求。创建的POISX线程时总是指定了CLONE_VM标志。
-
CLOEN_THREAD : 线程组
若设置了CLONE_THREAD,则会将子进程置于父进程的线程组中(也就是说创建出来的是一个线程,是一个儿子)。如果未设置,那么会将子进程置于新的线程组中(也就是说创建出来的是一个进程,需要独立门户)
POSIX标准规定,进程的所有线程共享同一进程ID(既每个线程调用getpid()都应返回相同值),LINUX从2.4版本开始引入了线程组(threads group),以满足这一需求。
一个线程组内的所有线程拥有同一父进程ID,既线程组与首线程ID相同。仅当线程组中所有线程都终止后,其父进程才会收到SIGCHILD信号(或其它终止信号)。这些行为符合POSIX线程规范的要求。
从Linux2.6开始,如果设置了CLONE_THREAD,同时也必须设置CLONE_SIGHAND。这也与POSIX线程标准的深入要求相契合。
-
CLONE_PARENT
创建的子进程的父进程是调用者的父进程,新进程与创建它的进程成了"兄弟"而不是"父子"
-
CLONE_SETTLS : 线程本地存储
如果设置了CLONE_SETTLS,那么参数tls所指向的user_desc结构对线程所使用的线程本地存储缓冲区加以描述
-
CLONE_NEWNS
在新的namespace启动子进程,namespace描述了进程的文件hierarchy
-
CLONE_PTRACE
若父进程被trace,子进程也被trace
|
/* * This creates a new process as a copy of the old one, * but does not actually start it yet. * * It copies the registers, and all the appropriate * parts of the process environment (as per the clone * flags). The actual kick-off is left to the caller. */ static __latent_entropy struct task_struct *copy_process( struct pid *pid, //in/out,用于指定/返回线程的pid int trace, int node, struct kernel_clone_args *args) { //1.定义返回值亦是retval和新的进程描述符task_struct结构p。 int pidfd = -1, retval; struct task_struct *p; struct multiprocess_signals delayed; struct file *pidfile = NULL; u64 clone_flags = args->flags; struct nsproxy *nsp = current->nsproxy;
/* * Don't allow sharing the root directory with processes in a different * namespace */ //2.标志合法性检查,当出现以下三种情况时,返回出错代号: //2.1 CLONE_NEWNS和CLONE_FS同时被设置,这两个标记不可兼容 // CLONE_NEWNS: 表示子进程需要自己的命名空间 // CLONE_FS: 表示子进程共享父进程的根目录和当前工作目录 // 在传统的Unix系统中,整个系统只有一个已经安装的文件系统树,每个进程从系统的根文件 // 系统开始,通过合法的路径可以访问任何文件。在2.6版本中的内核中,每个进程都可以拥 // 有属于自己的已安装文件系统树,也被称为命名空间。通常大多数进程都共享init进程所使 // 用的已安装文件系统树,只有在clone_flags中设置了CLONE_NEWNS标志时,才会为此新进 // 程开辟一个新的命名空间 if ((clone_flags & (CLONE_NEWNS|CLONE_FS)) == (CLONE_NEWNS|CLONE_FS)) return ERR_PTR(-EINVAL);
if ((clone_flags & (CLONE_NEWUSER|CLONE_FS)) == (CLONE_NEWUSER|CLONE_FS)) return ERR_PTR(-EINVAL);
/* * Thread groups must share signals as well, and detached threads * can only be started up within the thread group. */ //2.2 CLONE_THREAD被设置,但CLONE_SIGHAND未被设置 // 如果子进程和父进程属于同一个线程组(CLONE_THREAD被设置) // 那么子进程必须共享父进程的信号(CLONE_SIGHAND被设置) if ((clone_flags & CLONE_THREAD) && !(clone_flags & CLONE_SIGHAND)) return ERR_PTR(-EINVAL);
/* * Shared signal handlers imply shared VM. By way of the above, * thread groups also imply shared VM. Blocking this case allows * for various simplifications in other code. */ //2.3 CLONE_SIGHAND被设置,但CLONE_VM未被设置 // 如果子进程共享父进程的信号,(CLONE_SIGHAND被设置) // 那么必须同时共享父进程的内存描述符和所有的页表(CLONE_VM被设置) if ((clone_flags & CLONE_SIGHAND) && !(clone_flags & CLONE_VM)) return ERR_PTR(-EINVAL);
/* * Siblings of global init remain as zombies on exit since they are * not reaped by their parent (swapper). To solve this and to avoid * multi-rooted process trees, prevent global and container-inits * from creating siblings. */ if ((clone_flags & CLONE_PARENT) && current->signal->flags & SIGNAL_UNKILLABLE) return ERR_PTR(-EINVAL);
/* * If the new process will be in a different pid or user namespace * do not allow it to share a thread group with the forking task. */ if (clone_flags & CLONE_THREAD) { if ((clone_flags & (CLONE_NEWUSER | CLONE_NEWPID)) || (task_active_pid_ns(current) != nsp->pid_ns_for_children)) return ERR_PTR(-EINVAL); }
/* * If the new process will be in a different time namespace * do not allow it to share VM or a thread group with the forking task. */ if (clone_flags & (CLONE_THREAD | CLONE_VM)) { if (nsp->time_ns != nsp->time_ns_for_children) return ERR_PTR(-EINVAL); }
if (clone_flags & CLONE_PIDFD) { /* * - CLONE_DETACHED is blocked so that we can potentially * reuse it later for CLONE_PIDFD. * - CLONE_THREAD is blocked until someone really needs it. */ if (clone_flags & (CLONE_DETACHED | CLONE_THREAD)) return ERR_PTR(-EINVAL); }
/* * Force any signals received before this point to be delivered * before the fork happens. Collect up signals sent to multiple * processes that happen during the fork and delay them so that * they appear to happen after the fork. */ sigemptyset(&delayed.signal); INIT_HLIST_NODE(&delayed.node);
spin_lock_irq(¤t->sighand->siglock); if (!(clone_flags & CLONE_THREAD)) hlist_add_head(&delayed.node, ¤t->signal->multiprocess); recalc_sigpending(); spin_unlock_irq(¤t->sighand->siglock); retval = -ERESTARTNOINTR; if (signal_pending(current)) goto fork_out;
//3.对current线程,复制出一个新的进程描述符task_struct结构 // 通过dup_task_struct为子进程分配一个内核栈、thread_info结构和task_struct结构 // 注意,这里将当前进程current作为参数传递到此函数中 // 注意:这里赋值出来的新进程p,进程名和pid和current都是一样的 retval = -ENOMEM; p = dup_task_struct(current, node); if (!p) goto fork_out;
/* * This _must_ happen before we call free_task(), i.e. before we jump * to any of the bad_fork_* labels. This is to avoid freeing * p->set_child_tid which is (ab)used as a kthread's data pointer for * kernel threads (PF_KTHREAD). */ p->set_child_tid = (clone_flags & CLONE_CHILD_SETTID) ? args->child_tid : NULL; /* * Clear TID on mm_release()? */ p->clear_child_tid = (clone_flags & CLONE_CHILD_CLEARTID) ? args->child_tid : NULL;
//4.一些初始化 // 通过诸如ftrace_graph_init_task,rt_mutex_init_task完成某些数据结构的初始化 // 调用copy_creds复制证书(应该是复制权限及身份信息) ftrace_graph_init_task(p);
rt_mutex_init_task(p);
lockdep_assert_irqs_enabled(); #ifdef CONFIG_PROVE_LOCKING DEBUG_LOCKS_WARN_ON(!p->softirqs_enabled); #endif retval = -EAGAIN; if (atomic_read(&p->real_cred->user->processes) >= task_rlimit(p, RLIMIT_NPROC)) { if (p->real_cred->user != INIT_USER && !capable(CAP_SYS_RESOURCE) && !capable(CAP_SYS_ADMIN)) goto bad_fork_free; } current->flags &= ~PF_NPROC_EXCEEDED;
retval = copy_creds(p, clone_flags); if (retval < 0) goto bad_fork_free;
/* * If multiple threads are within copy_process(), then this check * triggers too late. This doesn't hurt, the check is only there * to stop root fork bombs. */ //5.检测系统中进程的总数量是否超过了max_threads所规定的进程最大数 retval = -EAGAIN; if (data_race(nr_threads >= max_threads)) goto bad_fork_cleanup_count;
//6.初始化子进程描述符p的各个字段,使得子进程和父进程逐渐区别出来,这部分工作 // 在copy_process函数中占据了相当长的一段的代码,不过考虑到task_struct结构 // 本身的复杂性,也就不足为奇了。这部分工作包含: // a) 初始化子进程中的children和sibling等队列头 // b) 初始化自旋锁和信号处理 // c) 初始化进程统计信息 // d) 初始化POSIX时钟 // e) 初始化调度相关的统计信息 // f) 初始化审计信息 // g) ... delayacct_tsk_init(p); /* Must remain after dup_task_struct() */ p->flags &= ~(PF_SUPERPRIV | PF_WQ_WORKER | PF_IDLE); p->flags |= PF_FORKNOEXEC; INIT_LIST_HEAD(&p->children); INIT_LIST_HEAD(&p->sibling); rcu_copy_process(p); p->vfork_done = NULL; spin_lock_init(&p->alloc_lock);
init_sigpending(&p->pending);
p->utime = p->stime = p->gtime = 0; #ifdef CONFIG_ARCH_HAS_SCALED_CPUTIME p->utimescaled = p->stimescaled = 0; #endif prev_cputime_init(&p->prev_cputime);
#ifdef CONFIG_VIRT_CPU_ACCOUNTING_GEN seqcount_init(&p->vtime.seqcount); p->vtime.starttime = 0; p->vtime.state = VTIME_INACTIVE; #endif
#ifdef CONFIG_IO_URING p->io_uring = NULL; #endif
#if defined(SPLIT_RSS_COUNTING) memset(&p->rss_stat, 0, sizeof(p->rss_stat)); #endif
p->default_timer_slack_ns = current->timer_slack_ns;
#ifdef CONFIG_PSI p->psi_flags = 0; #endif
task_io_accounting_init(&p->ioac); acct_clear_integrals(p);
posix_cputimers_init(&p->posix_cputimers);
p->io_context = NULL; audit_set_context(p, NULL); cgroup_fork(p); #ifdef CONFIG_NUMA p->mempolicy = mpol_dup(p->mempolicy); if (IS_ERR(p->mempolicy)) { retval = PTR_ERR(p->mempolicy); p->mempolicy = NULL; goto bad_fork_cleanup_threadgroup_lock; } #endif #ifdef CONFIG_CPUSETS p->cpuset_mem_spread_rotor = NUMA_NO_NODE; p->cpuset_slab_spread_rotor = NUMA_NO_NODE; seqcount_spinlock_init(&p->mems_allowed_seq, &p->alloc_lock); #endif #ifdef CONFIG_TRACE_IRQFLAGS memset(&p->irqtrace, 0, sizeof(p->irqtrace)); p->irqtrace.hardirq_disable_ip = _THIS_IP_; p->irqtrace.softirq_enable_ip = _THIS_IP_; p->softirqs_enabled = 1; p->softirq_context = 0; #endif
p->pagefault_disabled = 0;
#ifdef CONFIG_LOCKDEP lockdep_init_task(p); #endif
#ifdef CONFIG_DEBUG_MUTEXES p->blocked_on = NULL; /* not blocked yet */ #endif #ifdef CONFIG_BCACHE p->sequential_io = 0; p->sequential_io_avg = 0; #endif
/* Perform scheduler related setup. Assign this task to a CPU. */ //7.调用sched_fork函数执行调度器相关的设置,在该函数中完成下面的工作 // a) 为这个新进程分配CPU // b) 使得子进程的进程状态为TASK_RUNNING,并禁止内核抢占 // c) 并且,为了不对其他进程的调度产生影响,此时子进程共享父进程的时间片 retval = sched_fork(clone_flags, p); if (retval) goto bad_fork_cleanup_policy;
retval = perf_event_init_task(p); if (retval) goto bad_fork_cleanup_policy;
retval = audit_alloc(p); if (retval) goto bad_fork_cleanup_perf; /* copy all the process information */ shm_init_task(p); retval = security_task_alloc(p, clone_flags); if (retval) goto bad_fork_cleanup_audit;
//8.复制进程的所有信息 // 根据clone_flags的具体取值来为子进程拷贝或共享父进程的某些数据结构,如: // a) copy_semundo // b) 复制开放文件描述符(copy_files) // c) 复制符号信息(copy_sighand 和 copy_signal) // d) 复制进程内存(copy_mm) // e) 复制线程(copy_thread) retval = copy_semundo(clone_flags, p); if (retval) goto bad_fork_cleanup_security; retval = copy_files(clone_flags, p); if (retval) goto bad_fork_cleanup_semundo; retval = copy_fs(clone_flags, p); if (retval) goto bad_fork_cleanup_files; retval = copy_sighand(clone_flags, p); if (retval) goto bad_fork_cleanup_fs; retval = copy_signal(clone_flags, p); if (retval) goto bad_fork_cleanup_sighand; retval = copy_mm(clone_flags, p); if (retval) goto bad_fork_cleanup_signal; retval = copy_namespaces(clone_flags, p); if (retval) goto bad_fork_cleanup_mm; retval = copy_io(clone_flags, p); if (retval) goto bad_fork_cleanup_namespaces;
//8.1 复制线程 // 通过copy_thread函数更新子进程的内核栈和寄存器中的值,在之前的 // dup_task_struct中只是为子进程创建一个内核栈,这里才是真正的赋予它有意义的值 // 当父进程发出clone系统调用时,内核会将那个时候CPU中寄存器的值保存在父进程的 // 内核栈中,这里就是使用父进程内核栈中的值来更新子进程寄存器中的值 // 特别的,内核将子进程eax寄存器中的值强制赋值为0,这也就是为什么使用fork时 // 子进程返回值是0。而在do_fork函数中则返回的是子进程的pid // 另外,子进程的对应的thread_info结构中的esp字段会被初始化为子进程内核栈的基址 retval = copy_thread(clone_flags, args->stack, args->stack_size, p, args->tls); if (retval) goto bad_fork_cleanup_io;
stackleak_task_init(p);
//9.分配pid,如果没有指定pid的话,则重新申请一个pid // 用alloc_pid函数为这个新进程分配一个pid,Linux系统内的pid是循环使用的, // 采用位图方式来管理。简单的说,就是用每一位(bit)来标示该位所对应的pid是否被使用 if (pid != &init_struct_pid) { pid = alloc_pid(p->nsproxy->pid_ns_for_children, args->set_tid, args->set_tid_size); if (IS_ERR(pid)) { retval = PTR_ERR(pid); goto bad_fork_cleanup_thread; } }
/* * This has to happen after we've potentially unshared the file * descriptor table (so that the pidfd doesn't leak into the child * if the fd table isn't shared). */ //10.下面根据clone_flags的值继续更新子进程的某些属性,暂不分析了 if (clone_flags & CLONE_PIDFD) { retval = get_unused_fd_flags(O_RDWR | O_CLOEXEC); if (retval < 0) goto bad_fork_free_pid;
pidfd = retval;
pidfile = anon_inode_getfile("[pidfd]", &pidfd_fops, pid, O_RDWR | O_CLOEXEC); if (IS_ERR(pidfile)) { put_unused_fd(pidfd); retval = PTR_ERR(pidfile); goto bad_fork_free_pid; } get_pid(pid); /* held by pidfile now */
retval = put_user(pidfd, args->pidfd); if (retval) goto bad_fork_put_pidfd; }
#ifdef CONFIG_BLOCK p->plug = NULL; #endif //11.futex初始化 futex_init_task(p);
/* * sigaltstack should be cleared when sharing the same VM */ if ((clone_flags & (CLONE_VM|CLONE_VFORK)) == CLONE_VM) sas_ss_reset(p);
/* * Syscall tracing and stepping should be turned off in the * child regardless of CLONE_PTRACE. */ user_disable_single_step(p); clear_tsk_thread_flag(p, TIF_SYSCALL_TRACE); #ifdef TIF_SYSCALL_EMU clear_tsk_thread_flag(p, TIF_SYSCALL_EMU); #endif clear_tsk_latency_tracing(p);
/* ok, now we should be set up.. */ //12.这里设置pid和tgid, // 若设置了CLONE_THREAD,则会将子进程置于父进程的线程组中, // 若未设置,那么会将子进程置于新的线程组中 // 另外,POSIX标准规定,进程的所有线程共享同一进程ID(既每个线程调用 // getpid()都应返回相同值,也就是这里的tgid的值),LINUX从2.4版本 // 开始引入了线程组(threads group),以满足这一需求。 // 一个线程组内的所有线程拥有同一父进程ID,既线程组与首线程ID相同。仅当 // 线程组中所有线程都终止后,其父进程才会收到SIGCHILD信号(或其它终止信号)。 // 这些行为符合POSIX线程规范的要求。 p->pid = pid_nr(pid); if (clone_flags & CLONE_THREAD) { //12.1 创建的是线程 p->group_leader = current->group_leader; p->tgid = current->tgid; } else { //12.2 创建的是进程 p->group_leader = p; p->tgid = p->pid; }
p->nr_dirtied = 0; p->nr_dirtied_pause = 128 >> (PAGE_SHIFT - 10); p->dirty_paused_when = 0;
p->pdeath_signal = 0; INIT_LIST_HEAD(&p->thread_group); p->task_works = NULL;
/* * Ensure that the cgroup subsystem policies allow the new process to be * forked. It should be noted that the new process's css_set can be changed * between here and cgroup_post_fork() if an organisation operation is in * progress. */ retval = cgroup_can_fork(p, args); if (retval) goto bad_fork_put_pidfd;
/* * From this point on we must avoid any synchronous user-space * communication until we take the tasklist-lock. In particular, we do * not want user-space to be able to predict the process start-time by * stalling fork(2) after we recorded the start_time but before it is * visible to the system. */ //13.启动时间信息 p->start_time = ktime_get_ns(); p->start_boottime = ktime_get_boottime_ns();
/* * Make it visible to the rest of the system, but dont wake it up yet. * Need tasklist lock for parent etc handling! */ write_lock_irq(&tasklist_lock);
/* CLONE_PARENT re-uses the old parent */ //14.这里也是指定父子关系吗? // CLONE_PARENT: 创建的子进程的父进程是调用者的父进程,即新进程与 // 创建它的进程成了"兄弟"而不是"父子" // CLONE_THREAD: 子进程与父进程共享相同的线程群 if (clone_flags & (CLONE_PARENT|CLONE_THREAD)) { p->real_parent = current->real_parent; p->parent_exec_id = current->parent_exec_id; if (clone_flags & CLONE_THREAD) p->exit_signal = -1; else p->exit_signal = current->group_leader->exit_signal; } else { p->real_parent = current; p->parent_exec_id = current->self_exec_id; p->exit_signal = args->exit_signal; }
klp_copy_process(p);
spin_lock(¤t->sighand->siglock);
/* * Copy seccomp details explicitly here, in case they were changed * before holding sighand lock. */ copy_seccomp(p);
rseq_fork(p, clone_flags);
/* Don't start children in a dying pid namespace */ if (unlikely(!(ns_of_pid(pid)->pid_allocated & PIDNS_ADDING))) { retval = -ENOMEM; goto bad_fork_cancel_cgroup; }
/* Let kill terminate clone/fork in the middle */ if (fatal_signal_pending(current)) { retval = -EINTR; goto bad_fork_cancel_cgroup; }
/* past the last point of failure */ if (pidfile) fd_install(pidfd, pidfile);
init_task_pid_links(p); if (likely(p->pid)) { ptrace_init_task(p, (clone_flags & CLONE_PTRACE) || trace);
init_task_pid(p, PIDTYPE_PID, pid); if (thread_group_leader(p)) { init_task_pid(p, PIDTYPE_TGID, pid); init_task_pid(p, PIDTYPE_PGID, task_pgrp(current)); init_task_pid(p, PIDTYPE_SID, task_session(current));
if (is_child_reaper(pid)) { ns_of_pid(pid)->child_reaper = p; p->signal->flags |= SIGNAL_UNKILLABLE; } p->signal->shared_pending.signal = delayed.signal; p->signal->tty = tty_kref_get(current->signal->tty); /* * Inherit has_child_subreaper flag under the same * tasklist_lock with adding child to the process tree * for propagate_has_child_subreaper optimization. */ p->signal->has_child_subreaper = p->real_parent->signal->has_child_subreaper || p->real_parent->signal->is_child_subreaper; list_add_tail(&p->sibling, &p->real_parent->children); list_add_tail_rcu(&p->tasks, &init_task.tasks); attach_pid(p, PIDTYPE_TGID); attach_pid(p, PIDTYPE_PGID); attach_pid(p, PIDTYPE_SID); __this_cpu_inc(process_counts); } else { current->signal->nr_threads++; atomic_inc(¤t->signal->live); refcount_inc(¤t->signal->sigcnt); task_join_group_stop(p); list_add_tail_rcu(&p->thread_group, &p->group_leader->thread_group); list_add_tail_rcu(&p->thread_node, &p->signal->thread_head); } attach_pid(p, PIDTYPE_PID);
//15.nr_threads加一,表明新进程已经被加入到进程集合中 nr_threads++; }
//16.total_forks加一,以记录被创建进程数量 total_forks++; hlist_del_init(&delayed.node); spin_unlock(¤t->sighand->siglock); syscall_tracepoint_update(p); write_unlock_irq(&tasklist_lock);
proc_fork_connector(p); sched_post_fork(p); cgroup_post_fork(p, args); perf_event_fork(p);
trace_task_newtask(p, clone_flags); uprobe_copy_process(p, clone_flags);
copy_oom_score_adj(clone_flags, p);
//17.终于完毕了,返回新创建的线程的描述符 // copy_process执行完后返回do_fork,do_fork执行完毕后,虽然子进程 // 处于可运行状态,但是它并没有立刻运行。至于子进程何时执行这完全取决 // 于调度程序,也就是schedule()的事了 return p;
bad_fork_cancel_cgroup: spin_unlock(¤t->sighand->siglock); write_unlock_irq(&tasklist_lock); cgroup_cancel_fork(p, args); bad_fork_put_pidfd: if (clone_flags & CLONE_PIDFD) { fput(pidfile); put_unused_fd(pidfd); } bad_fork_free_pid: if (pid != &init_struct_pid) free_pid(pid); bad_fork_cleanup_thread: exit_thread(p); bad_fork_cleanup_io: if (p->io_context) exit_io_context(p); bad_fork_cleanup_namespaces: exit_task_namespaces(p); bad_fork_cleanup_mm: if (p->mm) { mm_clear_owner(p->mm, p); mmput(p->mm); } bad_fork_cleanup_signal: if (!(clone_flags & CLONE_THREAD)) free_signal_struct(p->signal); bad_fork_cleanup_sighand: __cleanup_sighand(p->sighand); bad_fork_cleanup_fs: exit_fs(p); /* blocking */ bad_fork_cleanup_files: exit_files(p); /* blocking */ bad_fork_cleanup_semundo: exit_sem(p); bad_fork_cleanup_security: security_task_free(p); bad_fork_cleanup_audit: audit_free(p); bad_fork_cleanup_perf: perf_event_free_task(p); bad_fork_cleanup_policy: lockdep_free_task(p); #ifdef CONFIG_NUMA mpol_put(p->mempolicy); bad_fork_cleanup_threadgroup_lock: #endif delayacct_tsk_free(p); bad_fork_cleanup_count: atomic_dec(&p->cred->user->processes); exit_creds(p); bad_fork_free: p->state = TASK_DEAD; put_task_stack(p); delayed_free_task(p); fork_out: spin_lock_irq(¤t->sighand->siglock); hlist_del_init(&delayed.node); spin_unlock_irq(¤t->sighand->siglock);
//18.注意:这里不一定是返回NULL,所以在判断是否创建成功时应该使用IS_ERR(task)判断 return ERR_PTR(retval); } |
4.3.1 dup_task_struct - 通过父线程拷贝一个新的线程
这里还没有区分出父线程和子线程
注意:这里复制出来的新的task,comm名字和pid和原来的都是一样的
|
static struct task_struct *dup_task_struct( struct task_struct *orig, //要复制的线程 int node) //从哪个node分配空间 { struct task_struct *tsk; unsigned long *stack; struct vm_struct *stack_vm_area __maybe_unused; int err;
//1.获取被拷贝的task所在的node,尽量保证子线程和父线程在同一个node中 if (node == NUMA_NO_NODE) node = tsk_fork_get_node(orig);
//2.从这个node中为子线程申请一个task_struct结构 tsk = alloc_task_struct_node(node); if (!tsk) return NULL;
//3.为子线程的栈申请空间 stack = alloc_thread_stack_node(tsk, node); if (!stack) goto free_tsk;
//4.这是在干啥?mem_cgroup相关的吗??? if (memcg_charge_kernel_stack(tsk)) goto free_stack;
stack_vm_area = task_stack_vm_area(tsk);
//5.直接将orig对应的task_struct结构中的内容,拷贝到tsk的task_struct结构中 // arch_dup_task_struct函数执行之后,子进程和父进程的描述符中的内容是完全 // 一样的,在copy_process的后面的逻辑中,会将子进程和父进程逐步区分开来 err = arch_dup_task_struct(tsk, orig);
/* * arch_dup_task_struct() clobbers the stack-related fields. Make * sure they're properly initialized before using any stack-related * functions again. */ //6.子进程的栈空间 tsk->stack = stack; #ifdef CONFIG_VMAP_STACK tsk->stack_vm_area = stack_vm_area; #endif #ifdef CONFIG_THREAD_INFO_IN_TASK refcount_set(&tsk->stack_refcount, 1); #endif
if (err) goto free_stack;
//7.SHADOW_CALL_STACK相关的信息 err = scs_prepare(tsk, node); if (err) goto free_stack;
#ifdef CONFIG_SECCOMP /* * We must handle setting up seccomp filters once we're under * the sighand lock in case orig has changed between now and * then. Until then, filter must be NULL to avoid messing up * the usage counts on the error path calling free_task. */ tsk->seccomp.filter = NULL; #endif
//8.直接将父进程org的thread_info结构中的所有内容, // 拷贝到子进程p的thread_info结构中去 setup_thread_stack(tsk, orig);
//9.清除相应的标记 clear_user_return_notifier(tsk); clear_tsk_need_resched(tsk);
//10.设置栈顶的标记,用于栈溢出检测 // 栈顶标记为STACK_END_MAGIC即0x57AC6E9D set_task_stack_end_magic(tsk);
#ifdef CONFIG_STACKPROTECTOR tsk->stack_canary = get_random_canary(); #endif
//11.这是在干啥??? if (orig->cpus_ptr == &orig->cpus_mask) tsk->cpus_ptr = &tsk->cpus_mask;
/* * One for the user space visible state that goes away when reaped. * One for the scheduler. */ //12.设置引用计数,注释解释了原因 refcount_set(&tsk->rcu_users, 2); /* One for the rcu users */ refcount_set(&tsk->usage, 1); #ifdef CONFIG_BLK_DEV_IO_TRACE tsk->btrace_seq = 0; #endif tsk->splice_pipe = NULL; tsk->task_frag.page = NULL; tsk->wake_q.next = NULL;
//13.系统中需要记录着所有的栈空间的大小,因为新创建了一个task,执行加操作 account_kernel_stack(tsk, 1);
kcov_task_init(tsk);
#ifdef CONFIG_FAULT_INJECTION tsk->fail_nth = 0; #endif
#ifdef CONFIG_BLK_CGROUP tsk->throttle_queue = NULL; tsk->use_memdelay = 0; #endif
#ifdef CONFIG_MEMCG tsk->active_memcg = NULL; #endif
//14.返回刚创建的子进程 return tsk;
free_stack: free_thread_stack(tsk); free_tsk: free_task_struct(tsk); return NULL; } |
4.3.2 setup_thread_stack
当进程的thread_info结构是处于栈空间的时候,该函数实现如下:
|
static inline void setup_thread_stack( struct task_struct *p, //子进程 struct task_struct *org) //父进程 { //1.将父进程org的thread_info结构中的所有内容,拷贝到子进程p的thread_info结构中去 // 注意: task_thread_info得到的是(struct thread_info *)类型的指针 // 所以*task_thread_info(org)得到的是org线程的thread_info中的内容 *task_thread_info(p) = *task_thread_info(org);
//2.重新设置新的子进程的thread_info结构中的task task_thread_info(p)->task = p; } |
4.3.3 copy_thread
|
asmlinkage void ret_from_fork(void) asm("ret_from_fork");
int copy_thread( unsigned long clone_flags, unsigned long stack_start, //指定栈的起始地址,也是回调函数的地址 unsigned long stk_sz, //用户空间线程用于指定栈大小 struct task_struct *p, //新创建的子进程 unsigned long tls) { //1.从栈中获取寄存器所在的地址 struct pt_regs *childregs = task_pt_regs(p);
memset(&p->thread.cpu_context, 0, sizeof(struct cpu_context));
/* * In case p was allocated the same task_struct pointer as some * other recently-exited task, make sure p is disassociated from * any cpu that may have run that now-exited task recently. * Otherwise we could erroneously skip reloading the FPSIMD * registers for p. */ fpsimd_flush_task_state(p);
ptrauth_thread_init_kernel(p);
//2.PF_KTHREAD用于标记自己是不是一个内核线程 if (likely(!(p->flags & PF_KTHREAD))) { //2.1 注意下面的C语言语法,是将current线程中的 // 寄存器内容,全部copy到新创建的子线程中去 *childregs = *current_pt_regs();
//2.2 注意:这里强制将x0赋值为0 childregs->regs[0] = 0;
/* * Read the current TLS pointer from tpidr_el0 as it may be * out-of-sync with the saved value. */ *task_user_tls(p) = read_sysreg(tpidr_el0);
//2.3 如果指定了栈地址,则赋值栈地址 // 需要注意的是,32位线程和64位线程的栈地址不一样 if (stack_start) { if (is_compat_thread(task_thread_info(p))) childregs->compat_sp = stack_start; else childregs->sp = stack_start; }
/* * If a TLS pointer was passed to clone, use it for the new * thread. */ if (clone_flags & CLONE_SETTLS) p->thread.uw.tp_value = tls; } else { //3.如果新创建的线程是一个内核线程,则首先将所有的寄存器清零,为啥捏???? memset(childregs, 0, sizeof(struct pt_regs)); childregs->pstate = PSR_MODE_EL1h; if (IS_ENABLED(CONFIG_ARM64_UAO) && cpus_have_const_cap(ARM64_HAS_UAO)) childregs->pstate |= PSR_UAO_BIT;
spectre_v4_enable_task_mitigation(p);
if (system_uses_irq_prio_masking()) childregs->pmr_save = GIC_PRIO_IRQON;
//3.1 指定栈的起始地址和栈大小 p->thread.cpu_context.x19 = stack_start; p->thread.cpu_context.x20 = stk_sz; } //4.指定返回地址和sp p->thread.cpu_context.pc = (unsigned long)ret_from_fork; p->thread.cpu_context.sp = (unsigned long)childregs;
ptrace_hw_copy_thread(p);
return 0; } |

文章评论
nubility👍 👍 👍