关注公众号不迷路:DumpStack
扫码加关注

目录
本文主要介绍trace32的simulator功能,利用trace32解dump,至于trace32在线调试技巧,后面有机会补充吧
一、启动trace32 Simulator
点击桌面TRACE32 Start图标
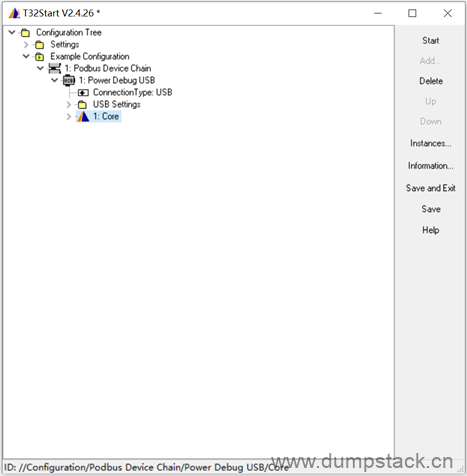
1.1 创建Simulator
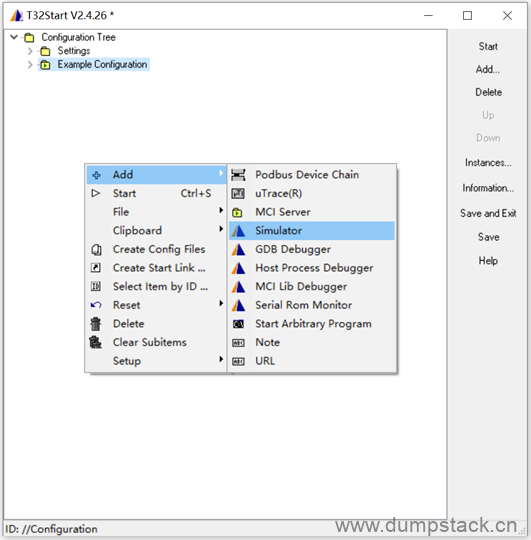
退到Example Configuration,在下面空白处:右键 -> Add -> Simulator
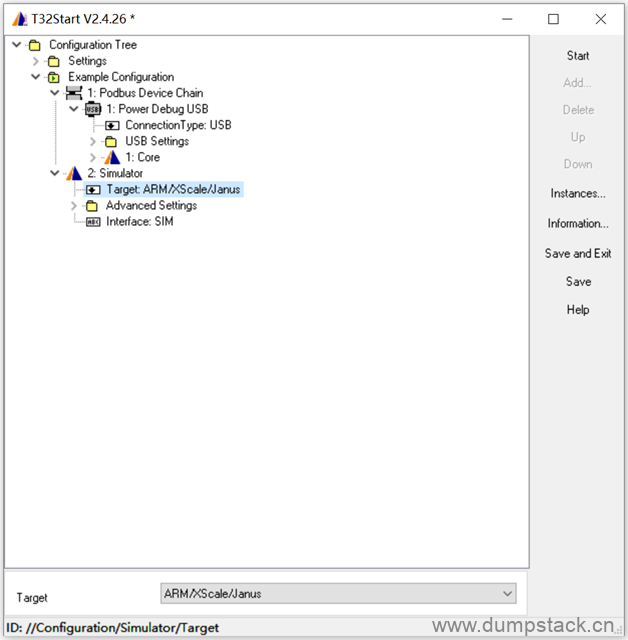
1.2 Target选择
展开Simulator标签,在Target处需要选择适合的平台
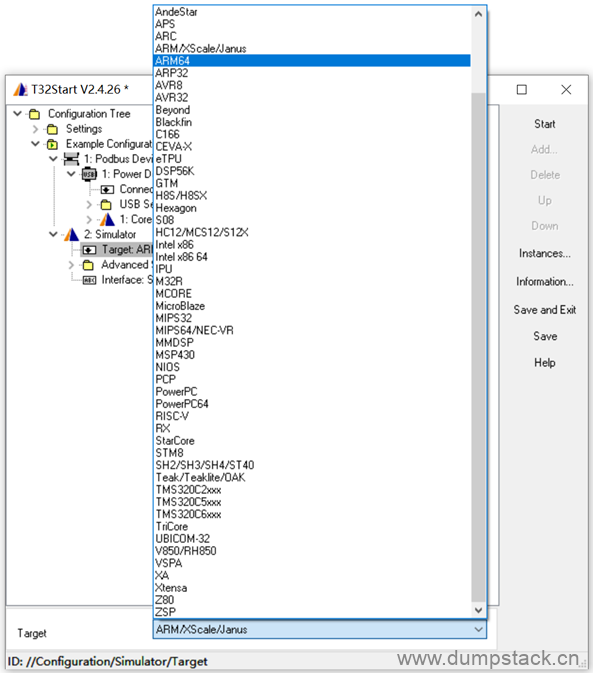
在下面Target处选择适合的平台,默认为ARM,本文选择选择ARM64,操作如下:
1.3 Advanced Settings
Advanced Settings用于配置一些参数,包括工作路径,帮助文档路径等,如下,这些参数我们一般很少改动,了解即可
各个参数官方解释如下:



全部配置完毕,点击start即可启动
二、常用命令
在下面的命令行输入命令,支持Tab键连续自动补全,不区分大小写
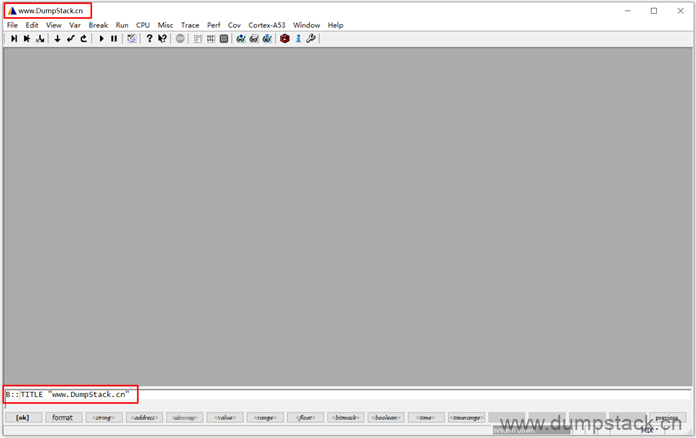
2.1 修改标题
首先我们改一下标题吧
| TITLE "www.DumpStack.cn" |
2.2 指定cpu类型
指定系统的CPU类型,该配置会影响后面反汇编的指令集,所有要选择和你目标系统一致的cpu类型,目标系统的cpu型号可以通过/proc/cpuinfo节点查看
PS:下面在输入命令的时候先输入system.cpu然后一直按Tab键,可以查看所有支持的cpu,点击previous按键可以查看上一页的标签
| SYStem.cpu CortexA53 |
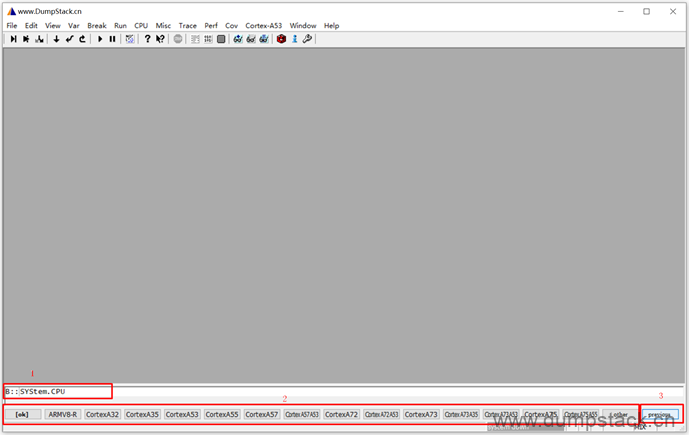
本例中我们选择CortexA53
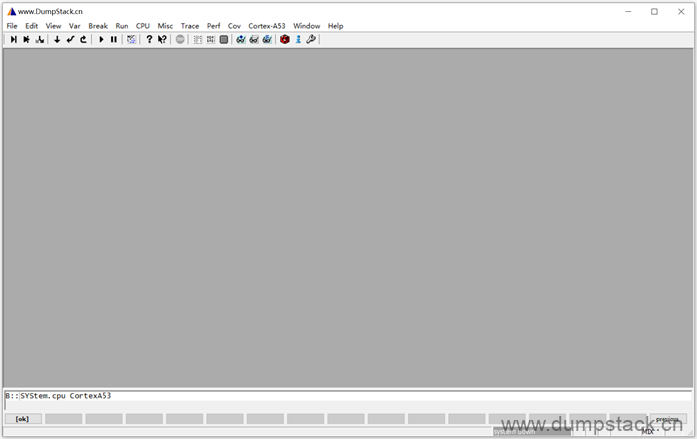
2.3 启动cpu
执行下面命令启动cpu,如果你有trace32仿真器并且连接了目标板,那么此命令会复位目标cpu,初始化连接,并运行Reset Vector
| SYStem.Up |
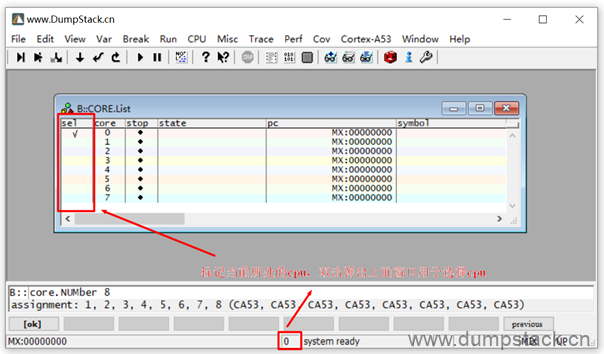
2.4 SMP多核设置
执行下面命令设置为8核
| sys.cpu ARMV9-A SYStem.CONFIG.CoreNumber 8 core.NUMber 8 sys.up |
按下面的方法可以指定切换到哪个cpu上,注意,因为每个cpu对应的x0~x31寄存器是不一样的,所以在切换cpu的时候这些寄存器的值也会发生变化,这个在查看异常线程的栈信息时尤为重要
PS:
对于高通的ramdump,我们利用simulator功能来仿真时,只设置了一个CPU核,但是一般情况下高通的的芯片是多核的,那么怎么来区分当前使用的是哪个CPU呢?
实际上dump解析出来的数据中,包含了coreN_regs.cmm这个脚本,这些脚本中分别存储了不同CPU的寄存器信息,我们通过在trace32加载不同的脚本来区分查看不同的CPU状态,实际上这些脚本中,只是通过设置了CPU的各个寄存器的值,从而切换到了不同CPU的运行现场,这时候我们完全可以不用配置多核。
2.5 查看寄存器
2.5.1 查看通用寄存器
执行下面命令可查看指定的寄存器的值
| PRINT Register(x0) PRINT Register(cpsr) |
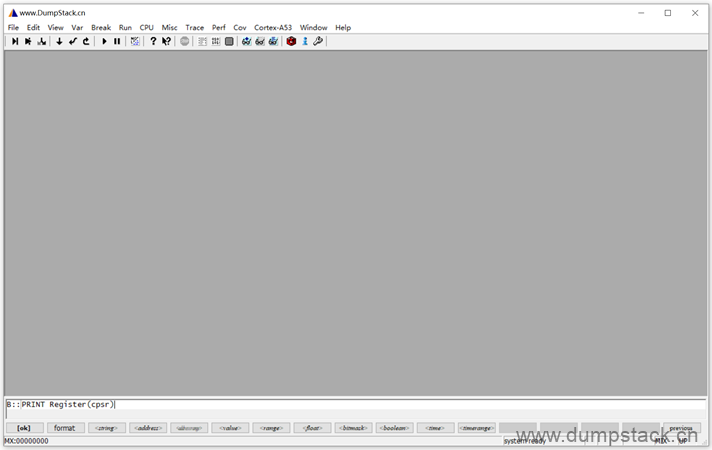
要查看的寄存器的值在这里显示
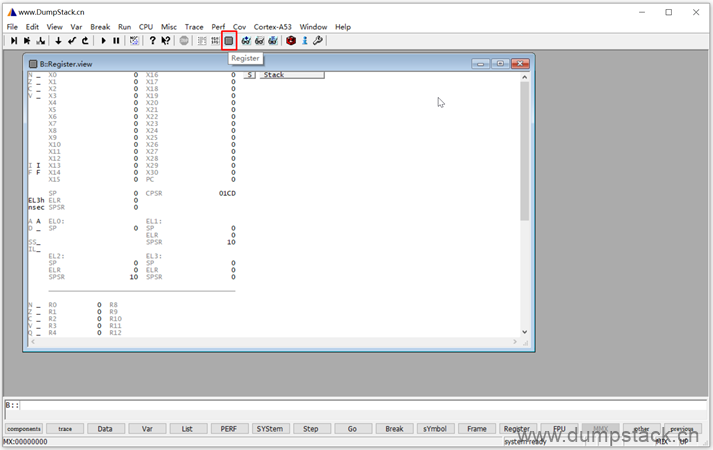
实际上还有一个更加快捷的方法,直接点击最上面的Register按钮,可以查看通用寄存器,如下
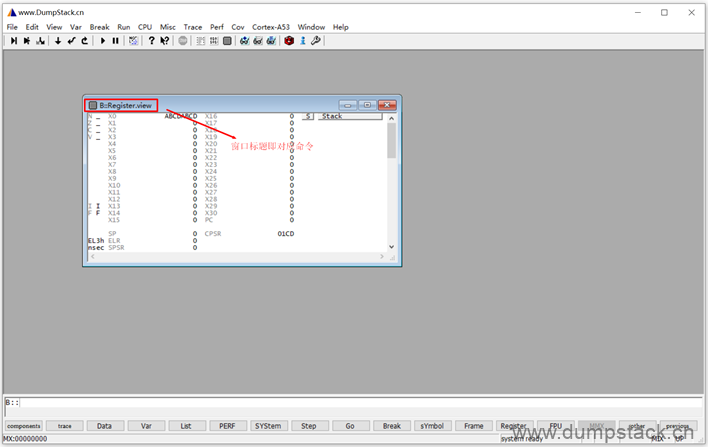
实际上上面弹出的弹框的标题,就是对应的命令,在下面命令栏输入窗口也会唤醒该窗口
2.5.2 查看系统寄存器
通过CPU -> Peripherals,可以查看系统寄存器的值
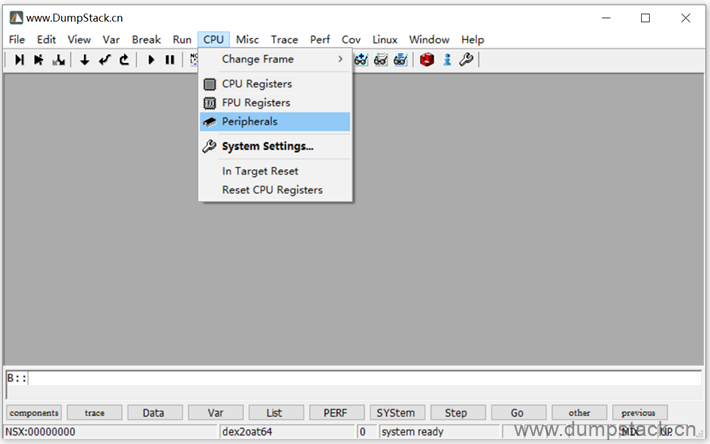
2.6 设置寄存器的值
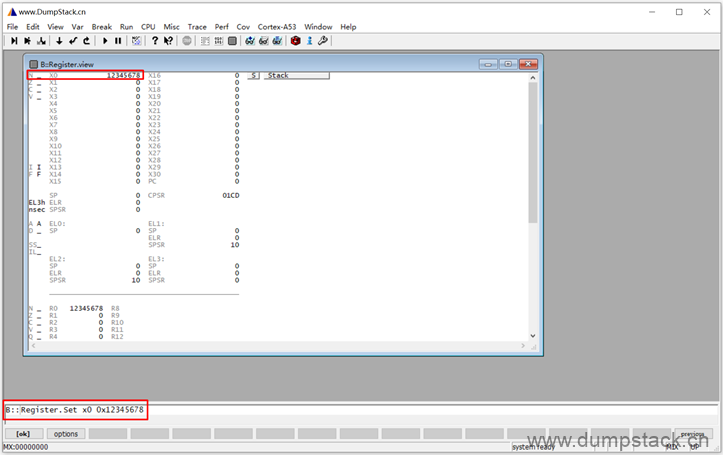
执行下面的命令设置寄存器的值
| ; 设置通用寄存器 Register.Set x0 0x12345678 ; 设置Non-secure bit为1,也就是非安全世界 Register.Set NS 1 ; 设置cpsr寄存器 Register.Set CPSR 0x3C5 ; 这里的SPR代表这Special Purpose Register,每个register大小为4Byte,后面跟着的0x30201是register number,所以这个命令修改的真实地址为0x30201 * 4。后面的代表写入数据的类型,最后一个参数为写入的数据值 Data.Set SPR:0x30201 %Quad 0x8294b000 |
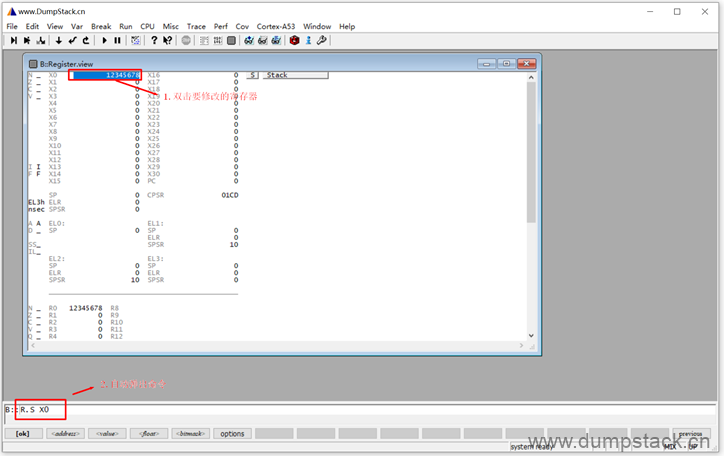
或者直接在下面界面中双击修改,双击要修改的寄存器后,下面命令自动弹出对应的命令,R.S是Register.Set的缩写
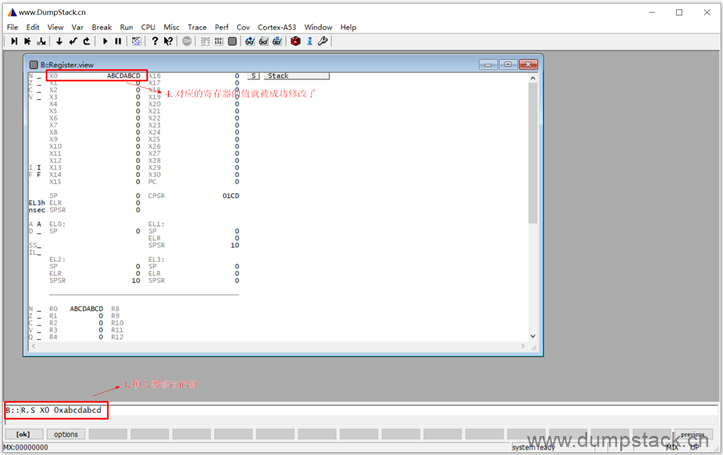
填入相应的值之后,回车确定,便修改成功了
2.7 MMU相关
常用命令如下
| ; 加载特定虚拟地址的page table ; PT代表从当前CPU的MMU中读取,由于前面我们用load对应的ramdump,并且配置MMU寄存器, ; 所以此时可以通过PT这个参数读取出来对应的page table,并且配置到我们trace32的仿真器中来使用 MMU.SCAN PT 0xFFFFFF8000000000--0xFFFFFFFFFFFFFFFF ; 打开MMU功能 mmu.on ; 列出对应起始地址之后的page table mmu.pt.list 0xffffff8000000000 |
2.8 查看内存的值
点击上面的Memory Dump按钮 -> 输入要查看的内存地址 -> 确定
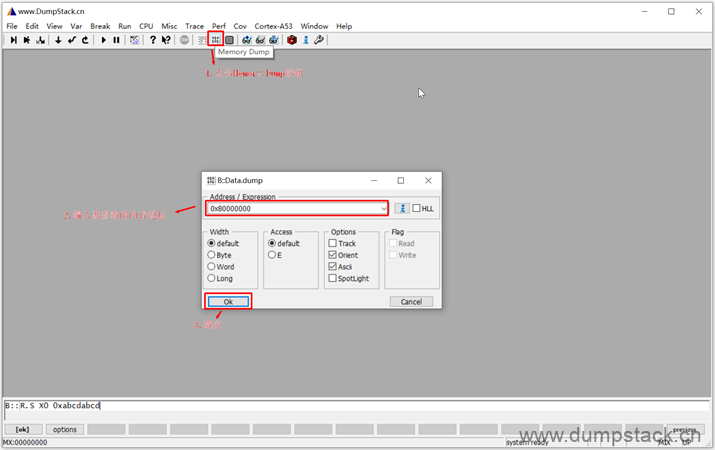
对应的内存如下:
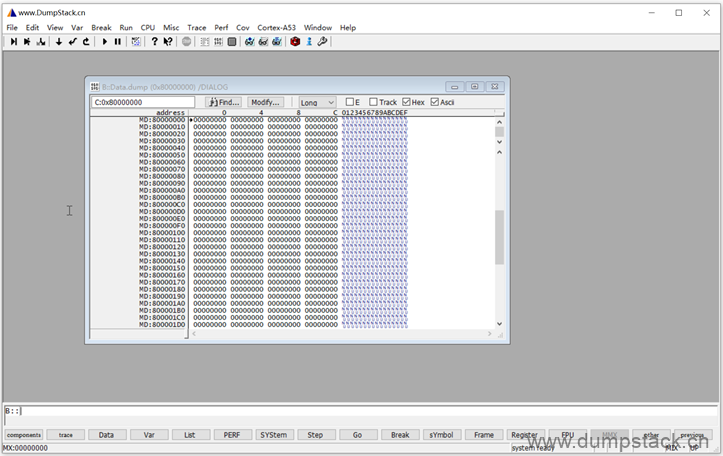
2.9 修改内存的值
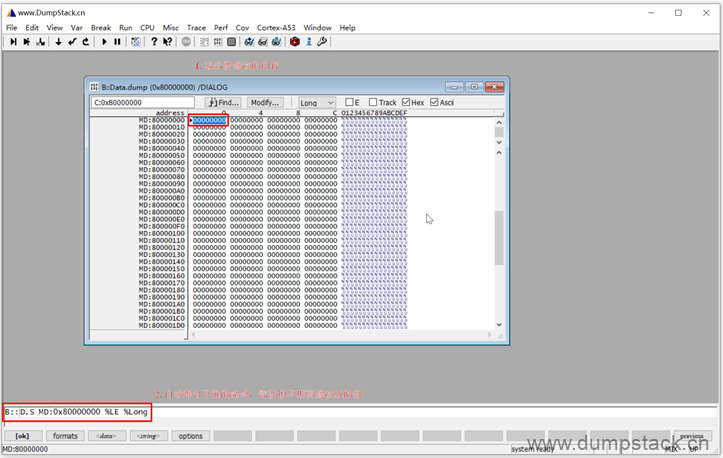
补充上要修改的值之后,回车确定,内存的值就被修改掉了
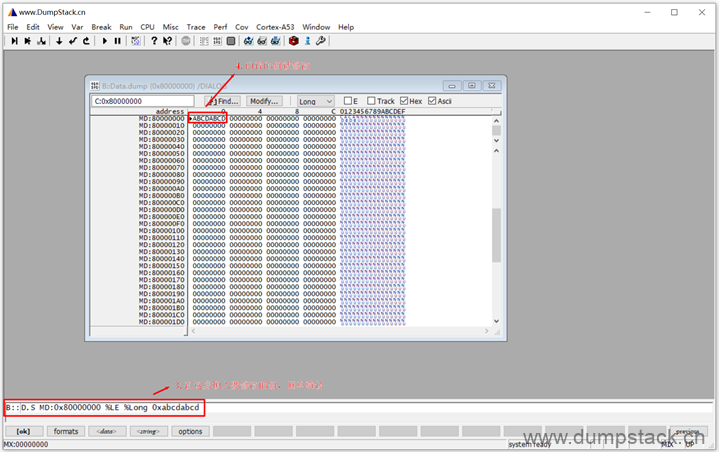
2.10 print/echo命令
print和echo命令参数基本一致,下面以print命令为例
| print linux_banner # 查看某个变量的地址,linux_banner是一个数组 print %d 0x32 # 进制转换,支持%Decimal(十进制),%Hex(十六进制),%BINary(二进制) |
2.11 加载vmlinux和ko文件
2.11.1 加载方式
点击file -> Load File,延后选择要加载的vmlinux或ko文件
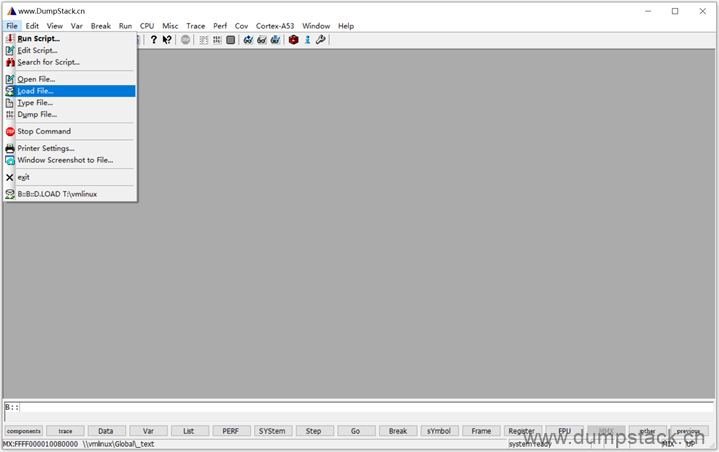
也可以通过下面命令加载,
加载elf文件命令,把指定的elf文件加载到目标设备或者仿真设备的0x1488800000地址上去。elf文件在编译时会把源文件的路径加入到elf文件中,我们后面加上/nocode代表没有对应的源码,trace32就不会去对应目录去查找源文件了。当然我们也可以通过/path来指定源码所在的目录,如下
| Data.LOAD.Elf T:\vmlinux Data.LOAD.Elf T:\vmlinux 0x1488800000 /nocode Data.LOAD.Elf T:\vmlinux 0x1488800000 /path T:\ |
2.11.2 修改符号表中的源码路径
通过下面命令加载,指定路径为"T:\",这是一个通过samba映射过来的网盘
| Data.LOAD.Elf T:\vmlinux 0x1488800000 /path T:\ |
查看符号表的时候,会提示下面的警告信息
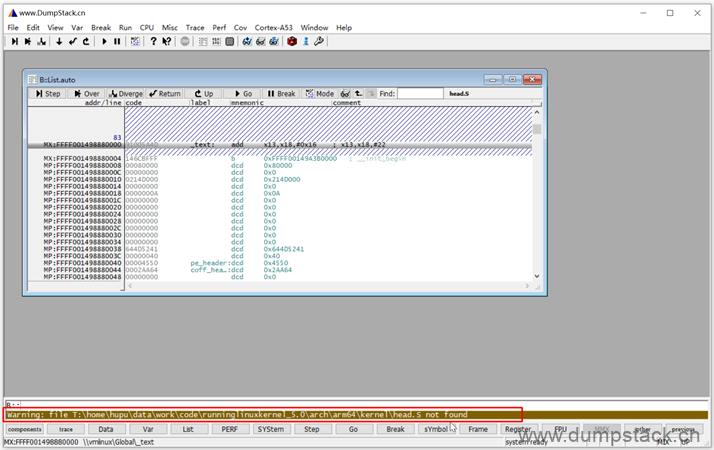
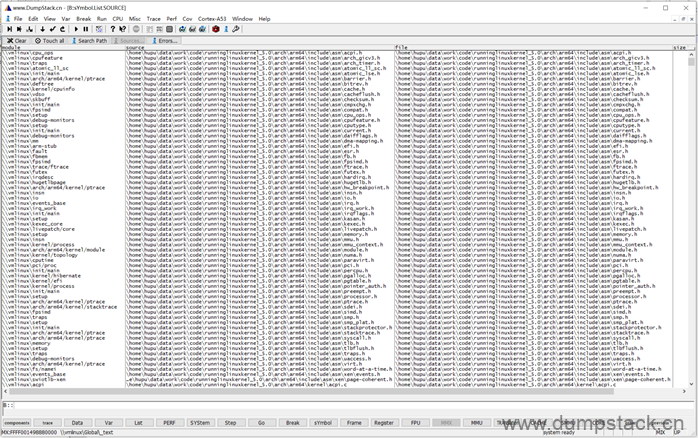
通过View -> Symbols -> Source -> File Names可以查看文件的映射关系
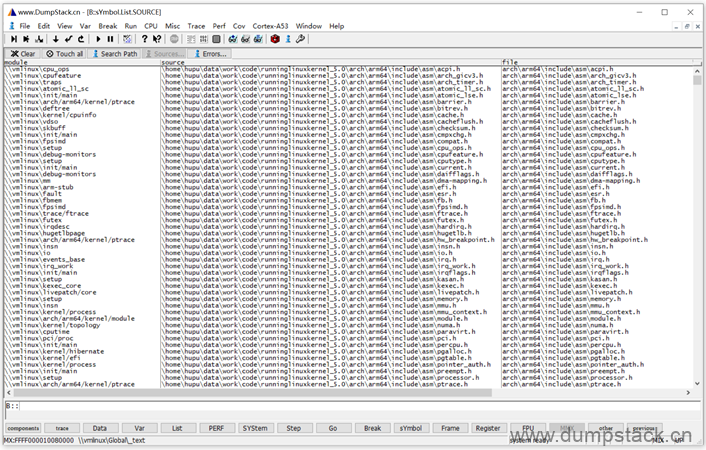
执行下面命令后,表示取出elf文件中的前缀路径,从7层开始映射,前面的路径移除
| Data.LOAD T:\vmlinux /StripPART 7 |
路径映射关系变为:
| \home\hupu\data\work\code\runninglinuxkernel_5.0\arch\arm\include\asm\acpi.h 被替换为 arch\arm\include\asm\acpi.h |
如下图:
2.11.3 查看指定函数的汇编
View -> Symbols标签如下,可查看函数/变量/数据结构等信息
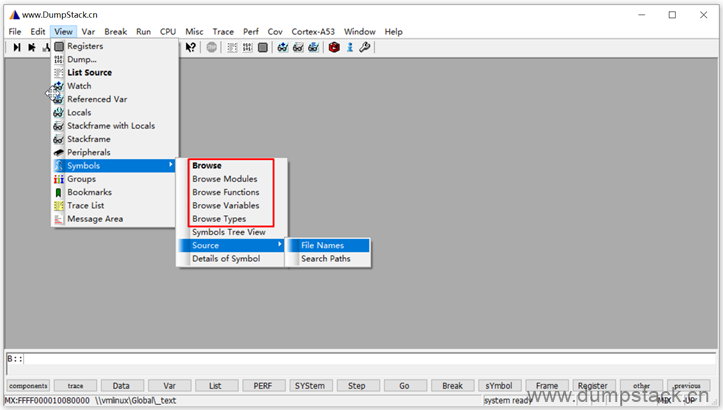
下面我们来看一下start_kernel的反汇编代码
打开View -> Symbols -> Browse Functions,界面如下
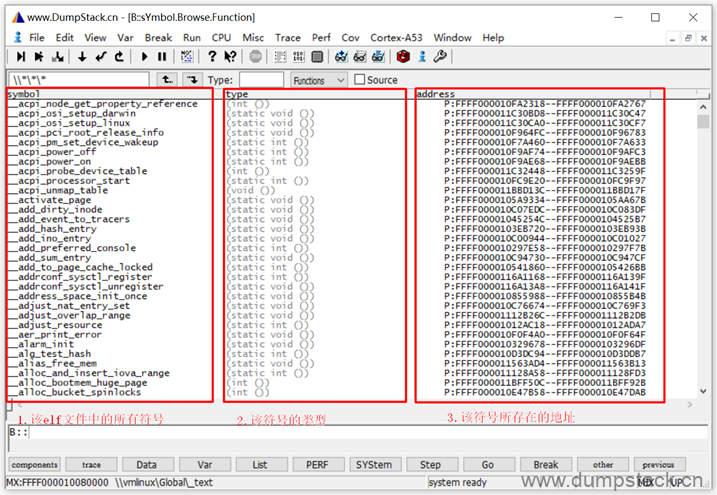
在下面位置输入要查看的函数名
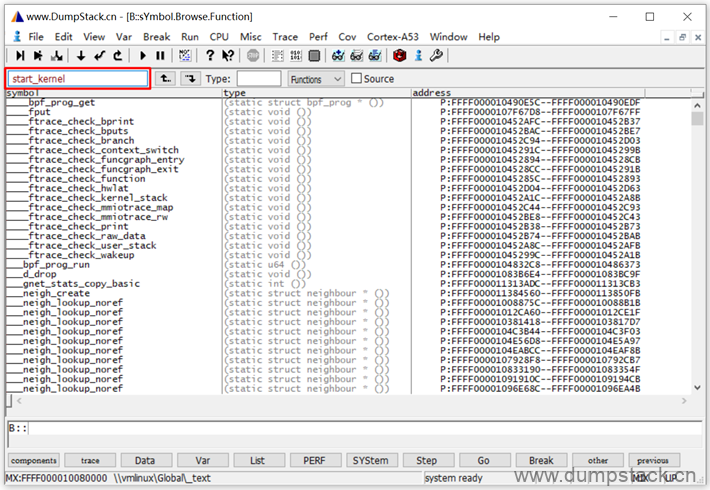
回车后就能看到对应的汇编
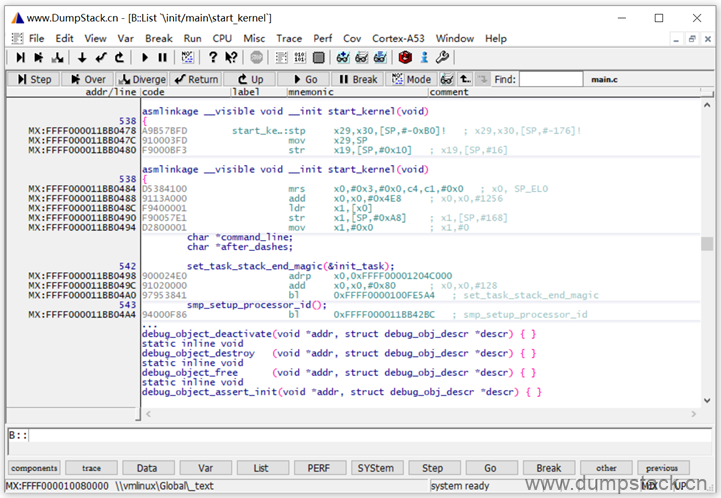
2.11.4 查看指定数据结构的成员
打开View -> Symbols -> Browse Types,界面如下
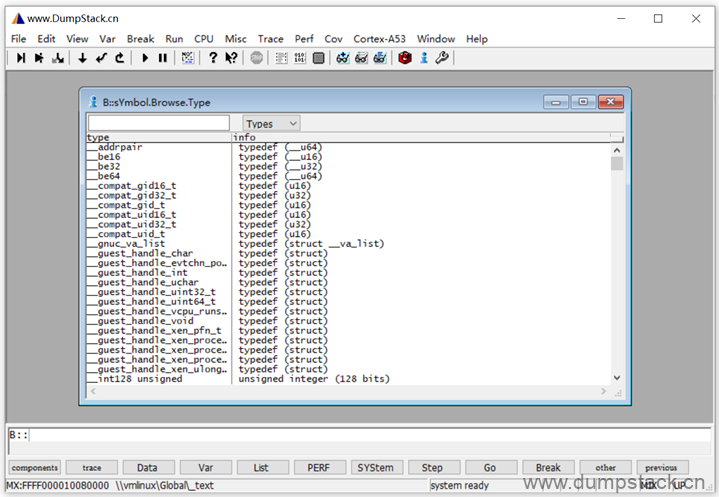
在下面搜索框内输入要查看的数据结构名称
注意:前面需要加上关键子struct或enmu等
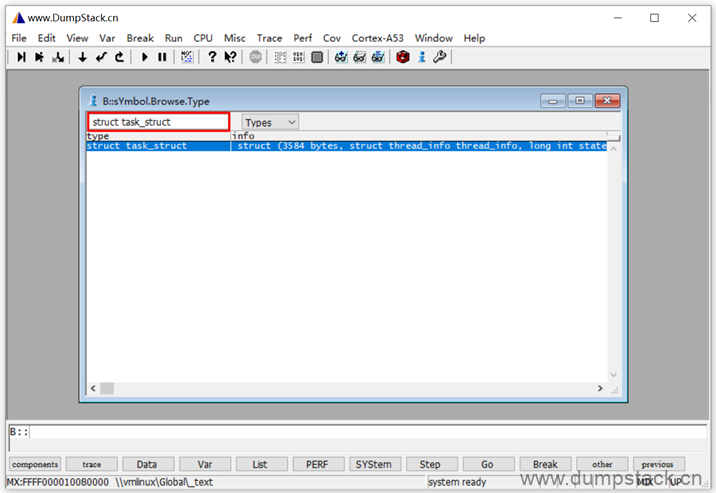
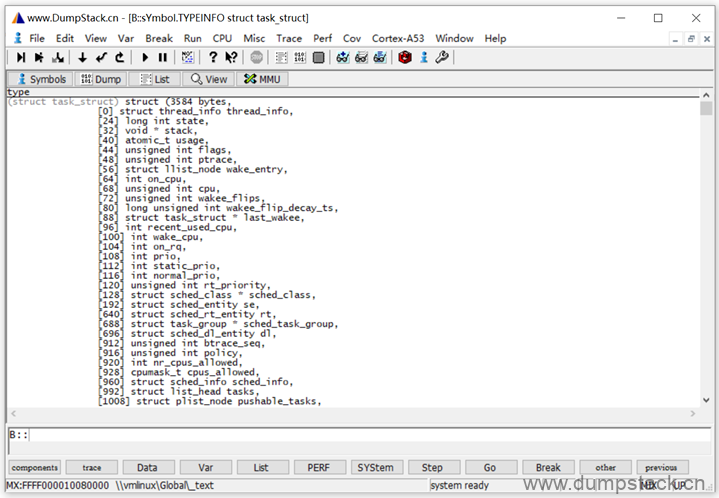
回车如下,不加能查看该数据结构由哪些成员,还能看到成员的偏移量,太牛逼了
下面再看一个enmu类型
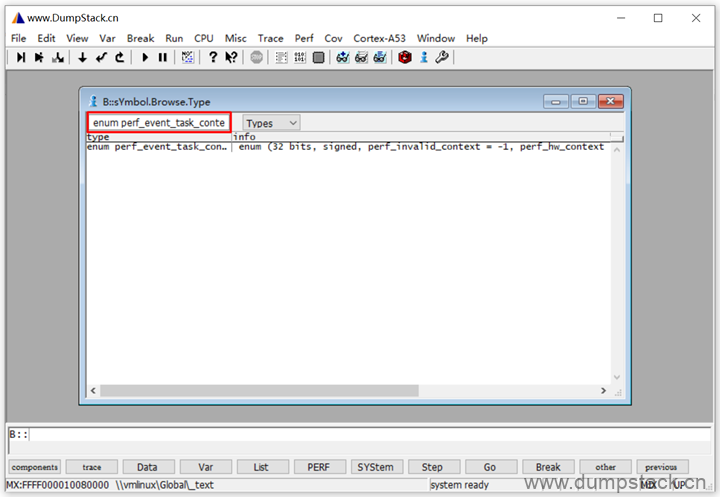
内容如下:
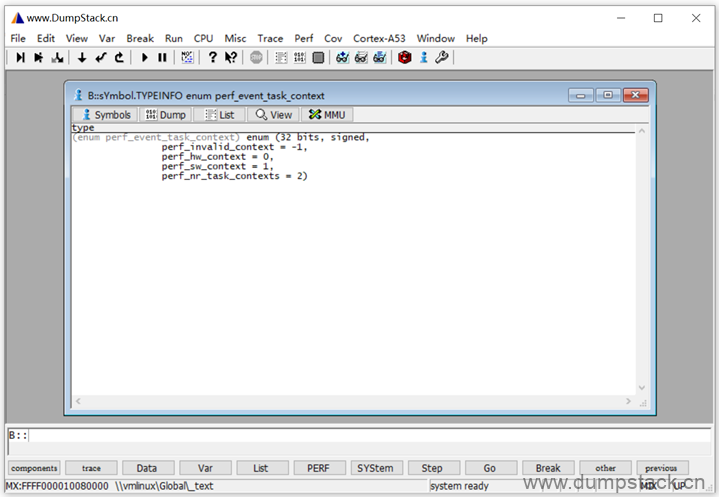
2.11.5 加载ko文件
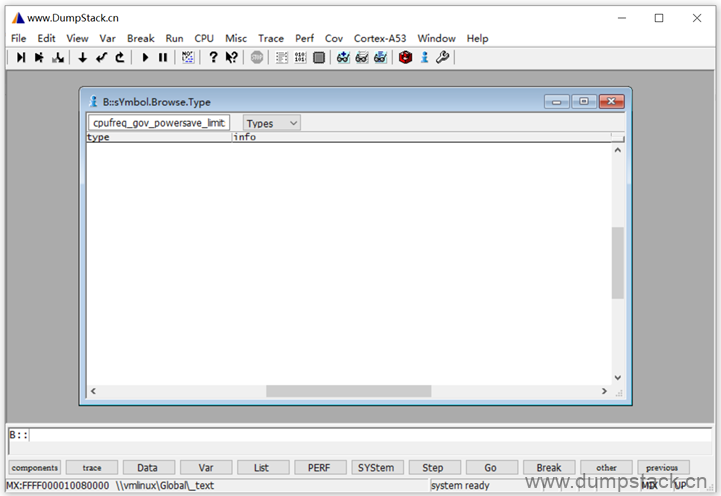
有些变量和符号是在ko文件中,下面我们以cpufreq_powersave.ko文件为了,该文件中有一个函数cpufreq_gov_powersave_limits,如下,在未加载之前函数是空的,因为这个函数不在vmlinux中
加载ko的方法如下:
| # 0x80000000表示将这个ko加载到哪里 # /NoClear表示保留已经加载的vmlinux符号表,如果不带该参数的话,vmlinux的符号表会被删除 # /RELOCSTRIPPED表示在加载时不就行重定位 Data.LOAD.Elf t:\cpufreq_powersave.ko 0x80000000 /NoClear /RELOCSTRIPPED #或者使用下面命令将代码段重定位 Data.LOAD.Elf t:\cpufreq_powersave.ko /NoClear /RELOC .text AT 0x0 # 下面指定加载的驱动名,/reloctype指定加载的文件是一个ko Data.LOAD.Elf t:\cpufreq_powersave.ko /NoCODE /NoClear /NAME cpufreq_powersave /reloctype 0x3 |
2.12 加载二进制文件
加载binary文件命令,把指定文件加载到指定地址,比如我们抓取到的故障现场的快照ramdump。除了起始地址外,还可以加上一个range参数,作为加载范围。加载时会以binary的大小和range之间选小值作为限制。
| data.load.binary DDRCS0_0.BIN 0x80000000 |
2.13 工作目录查看和切换
| pwd # 查看当前工作目录 cd t:\ # 进入指定的目录 dir或者ls # 查看当前目录下有哪些文件 history # 查看命令执行的历史 cd.do my_dir/test.cmm # 进入指定的目录,并执行脚本 |
2.14 执行cmm文件
进入到目标目录,并执行对应的cmm脚本
| do test.cmm |
或者通过File -> Edit Scripts打开对应的cmm文件,然后点击下面的Debug进入下面的调试界面
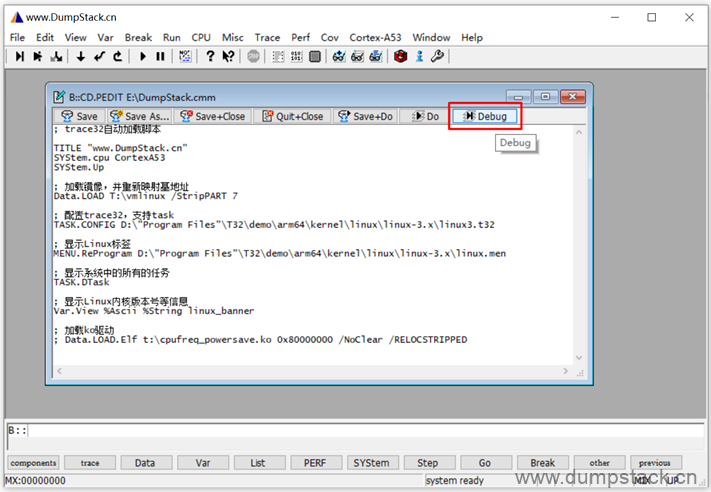
调试界面如下,可以但不调试cmm中的某个脚本
2.15 导出log_buf里面的日志
执行下面命令可以将一个数组里面的所有字符串导出来
ps: 如果是在解dump文件,可以通过下面的方式直接导出log_buf中的dmesg信息,因为我手里现在没有dump文件,所有这里只是将vmlinux中记录的一个静态版本信息导出了
| Data.SAVE.Binary E:\aaa.log linux_banner++100 |
示例如下:
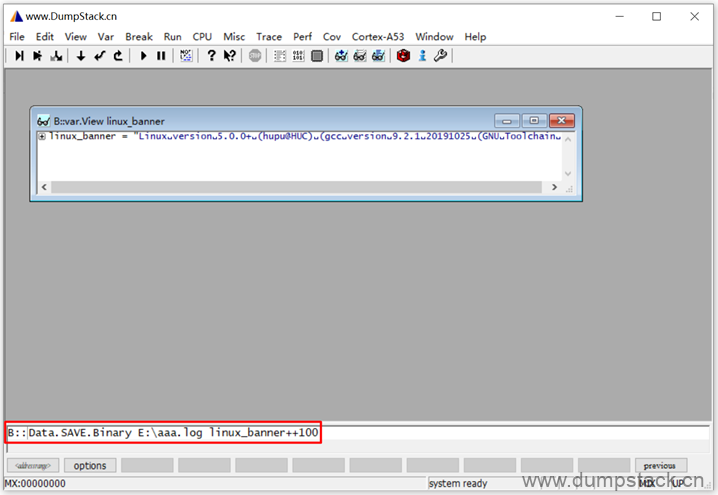
2.16 查看数据时切换显示的格式
如下图,执行下面命令可以查看指定的数组,但是默认是按照十进制显示的
| var.View linux_banner |
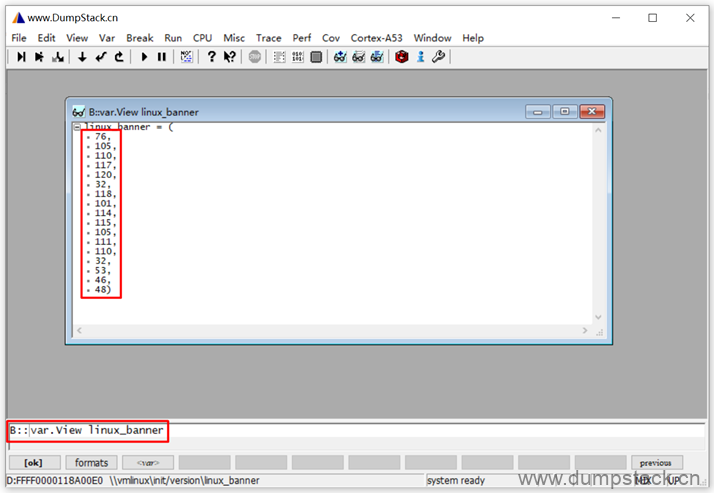
点击每个数据前面的黑色小点,可实现"十进制 -> 十六进制 -> ASCII码"的顺序切换格式,如下
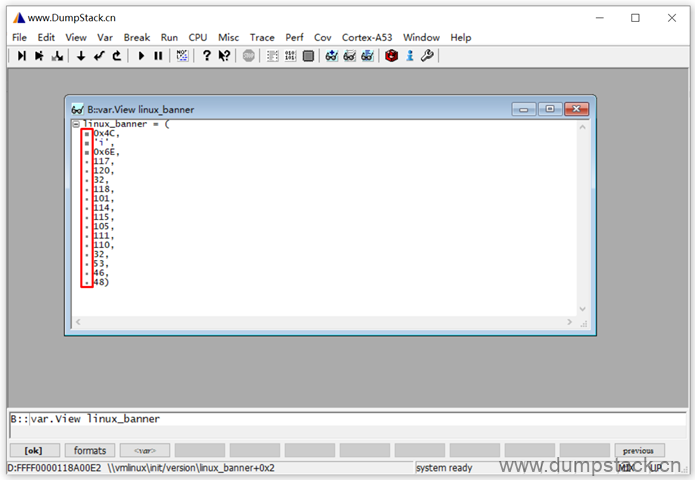
也可以直接在变量名上右键->Format,在弹出的对话框中完成格式设置
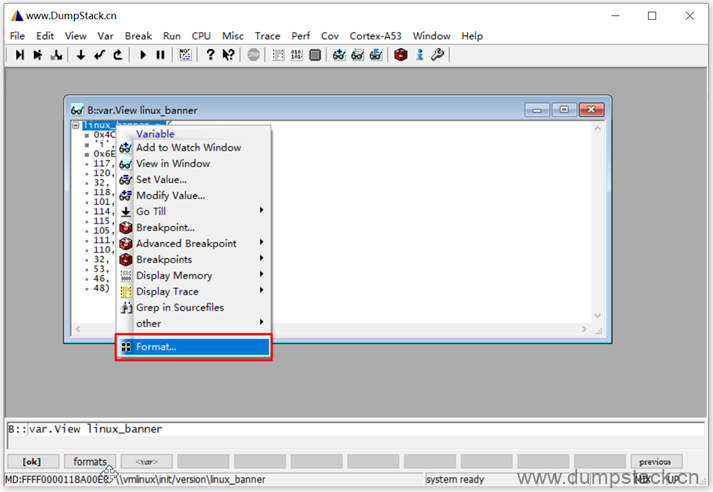
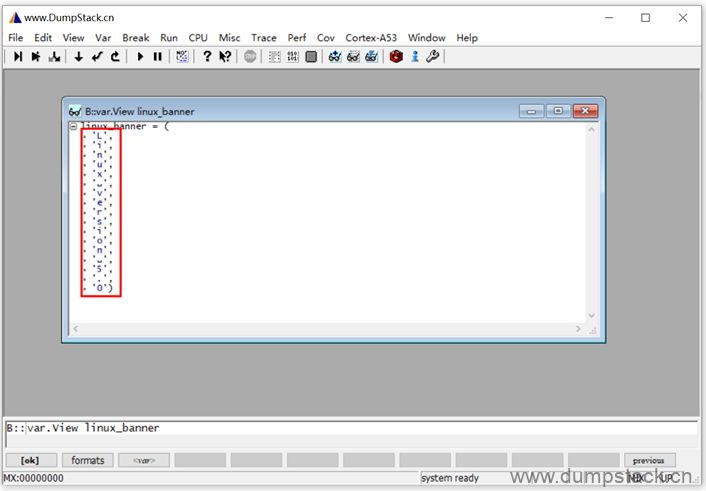
这里我选择先转为ascii码,按照字符串显示,如下
显示如下,是不是舒服多了
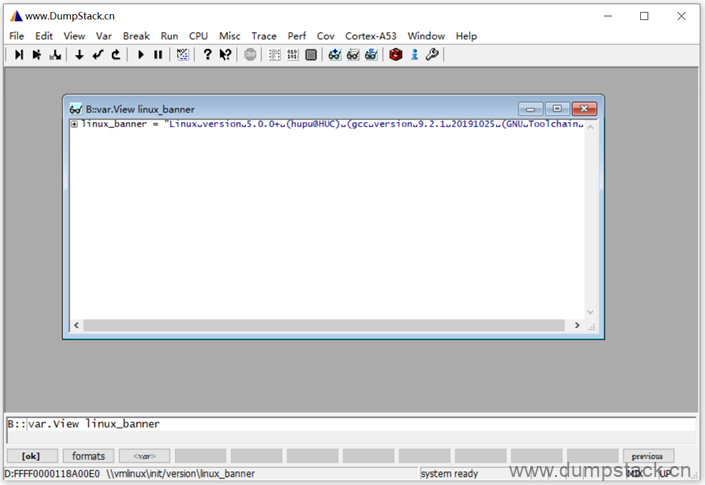
2.17 trace32对linux的支持
| ; 通过指定的配置文件来配置trace32的RTOS仿真调试器,用来配置和加载系统内核用的 ; Trace32提前定义了一些可用的系统配置文件 task.config /opt/t32/demo/arm64/kernel/linux/linux-3.x/linux3.t32 ; 启动预定义的linux系统对应的trace32界面 menu.reprogram /opt/t32/demo/arm64/kernel/linux/linux-3.x/linux.men |
2.18 trace强大的帮助系统
trace32有很强大的帮助系统,可通过help命令或者F1按键唤醒
trace32有上千条命令,每个命令又有几十到几百个参数,不可能所有的命令和参数都能记住。如下,命令输入到一半不知道参数了怎么办?按下F1按键,会弹出下面帮助对话框,并弹出pdf帮助文档
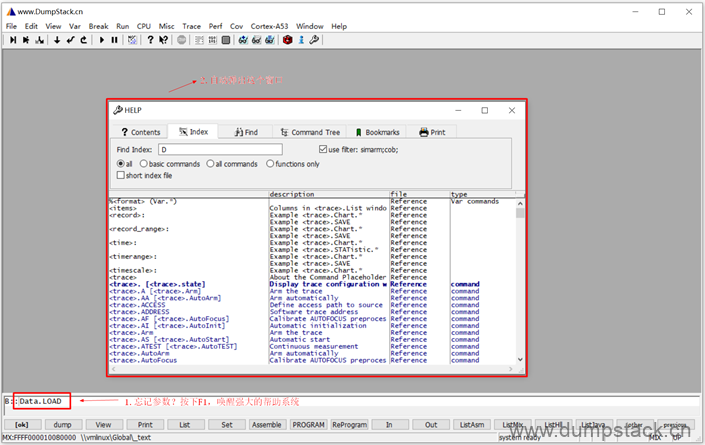
自动弹出pdf的帮助文档,并直接定位到对应的指令处,太牛逼了
或者通过最上面的Help标签进入帮助系统,如下
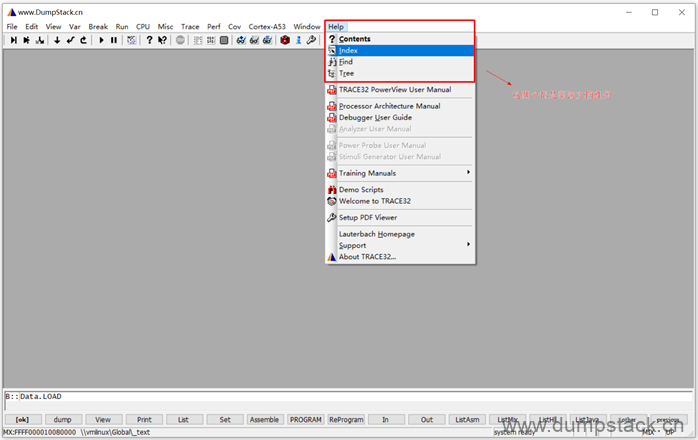
下面的Contents标签显示的是帮助系统的目录,对应一个个pdf文件,双击打开对应的pdf文件
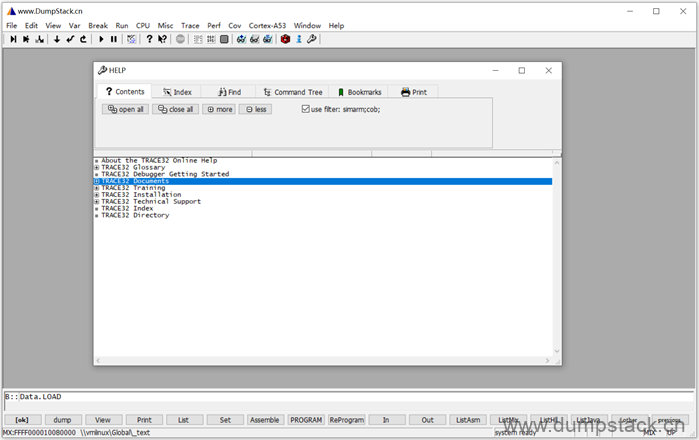
在下面index标签中,输入要查询的命令,下面就会出现命令可接的参数,双击便跳转到对应的pdf帮助文档
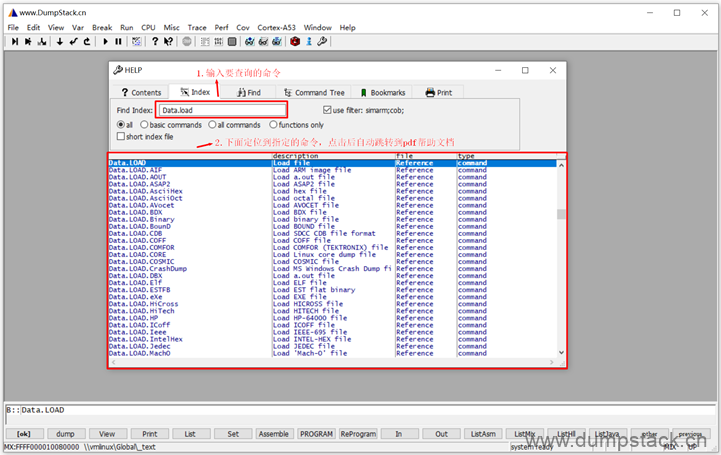
在Find标签,输入指定的命令关键字,可以在所有pdf文档中查找相关信息,双击跳转
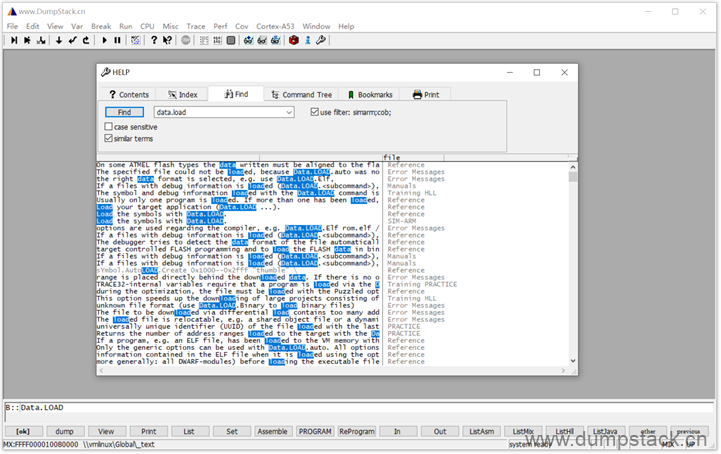
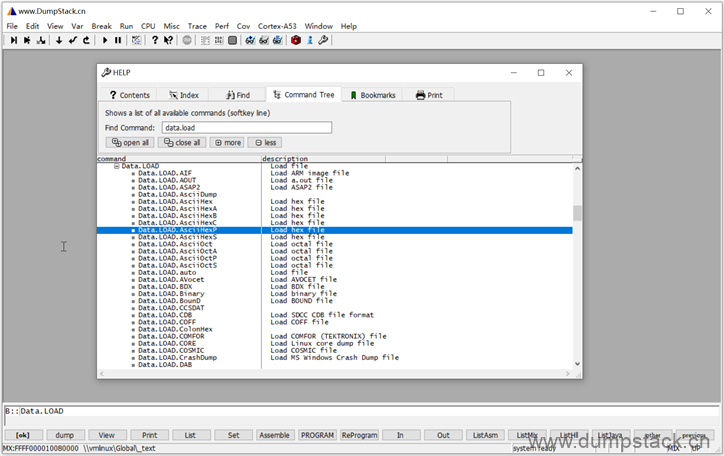
在Command Tree标签,可以查看命令的树形关系,依然是双击跳转
三、进阶篇
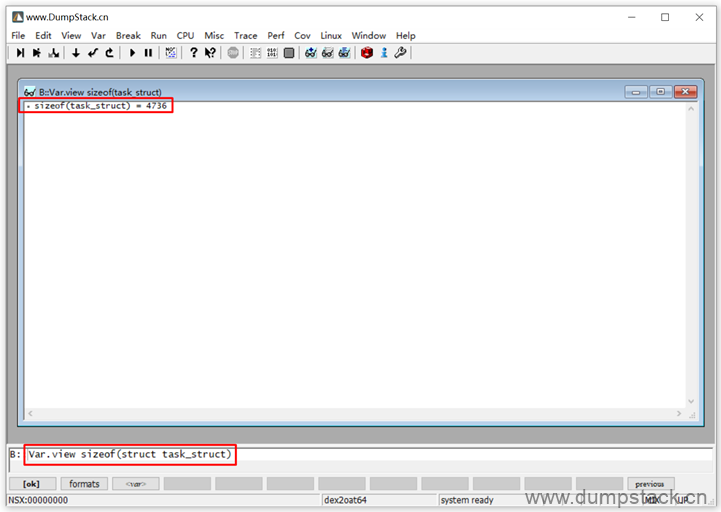
3.1 查看数据类型的大小
命令如下:
| Var.view sizeof(struct task_struct) 或者 Var.view sizeof(task_struct) |
3.2 怎样查看某个变量的地址
在变量名上右键 -> Display Memory -> Dump
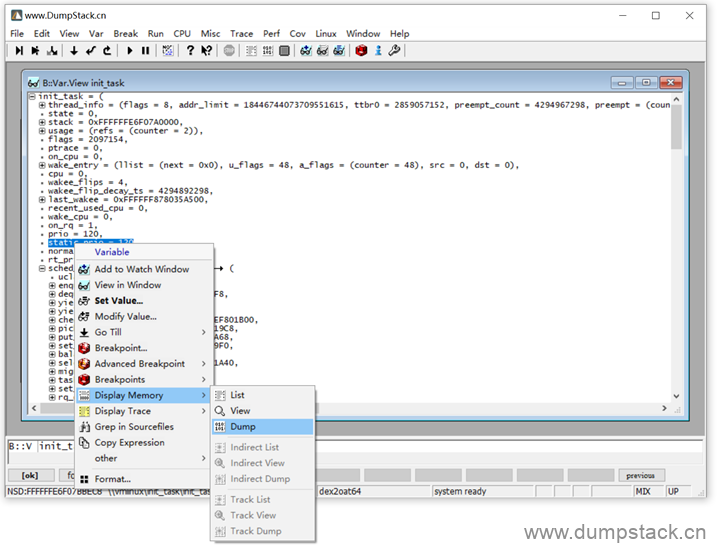
带箭头的那个内存空间就是该变量对应的地址
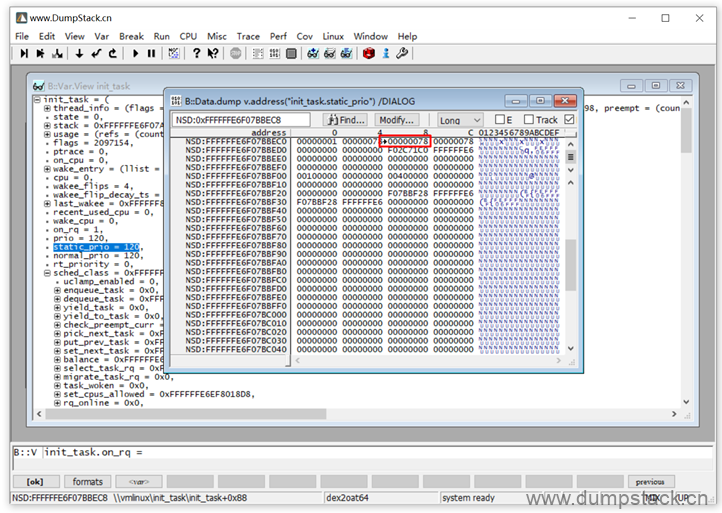
3.3 已知地址,确定变量/函数名
例如我们已经知道一个符号(可能是变量或者函数)的地址,怎么确定这个地址是一个变量还是一个函数呢?如果是变量的话,变量名是啥?变量定义的位置在哪?如果是函数,函数名是啥?函数定义的位置又在哪呢?
例如我们已经知道了一个符号的地址为0xFFFF000011BB0478如下,通过View -> Dump查看这个地址的内存信息,在地址的内容上右键 -> View Info
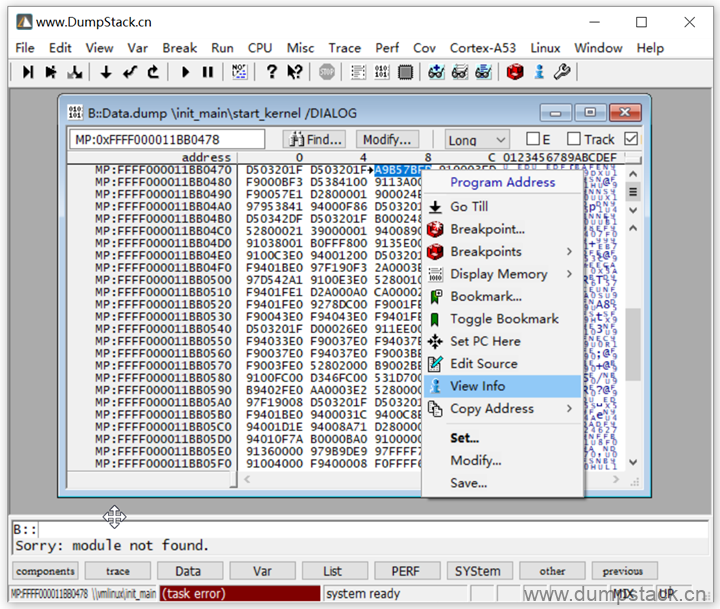
调出的窗口如下,下面的function关键字表示这个地址对应的是一个函数,start_kernel就是函数名,下面还指定了函数定义的位置
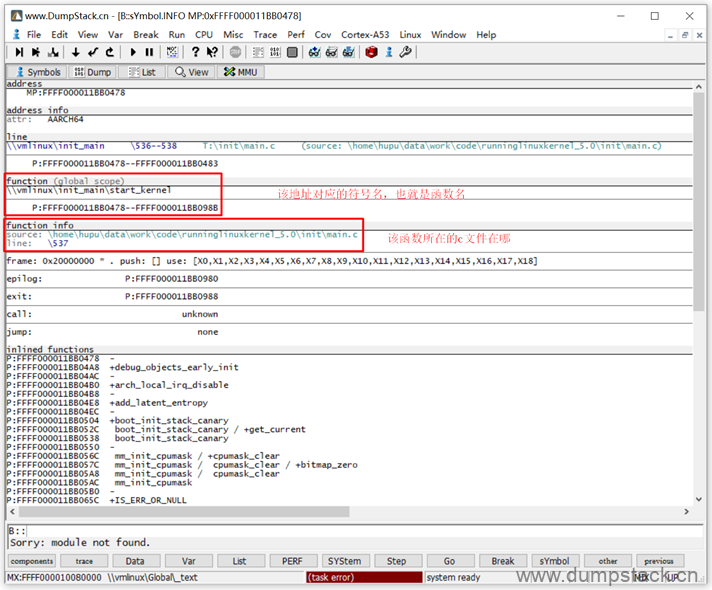
又例如,我们已经知道一个符号的地址为0xFFFF000011DA0B80,依然是通过View -> Dump先查看这个地址的内存信息,然后在地址的内容上右键 -> View Info
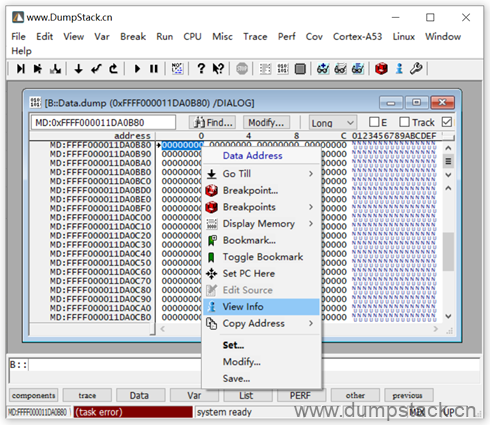
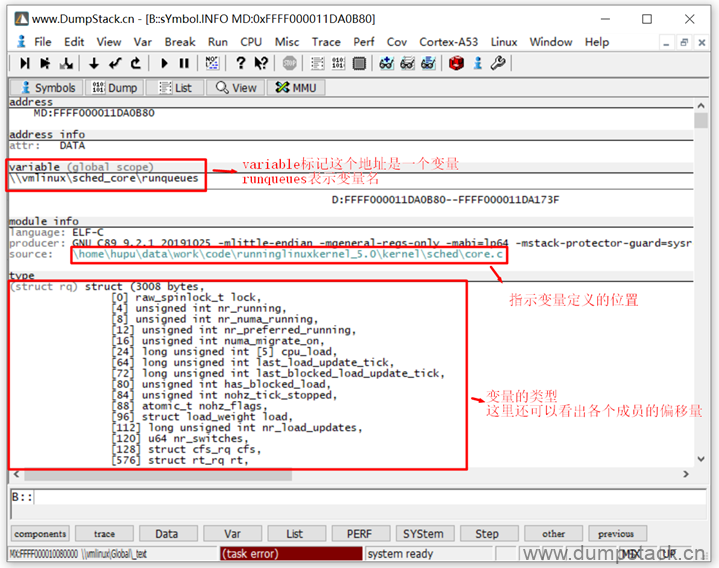
调出的窗口如下,variable表示这个位置对应的是一个变量,变量名为runqueues,变量的类型为struct rq结构,变量定义的位置为kernel/sched/core.c中
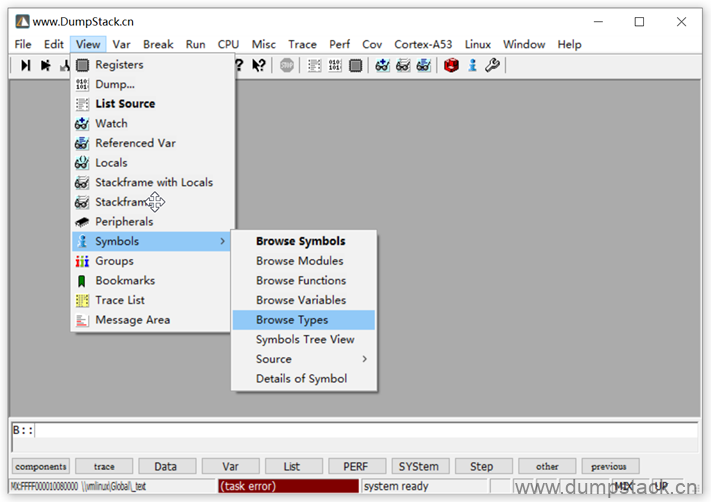
3.4 查看数据结构中各个成员的偏移量
第一步:View -> Symbols -> Browse Types
第二步:属于要查看的数据类型
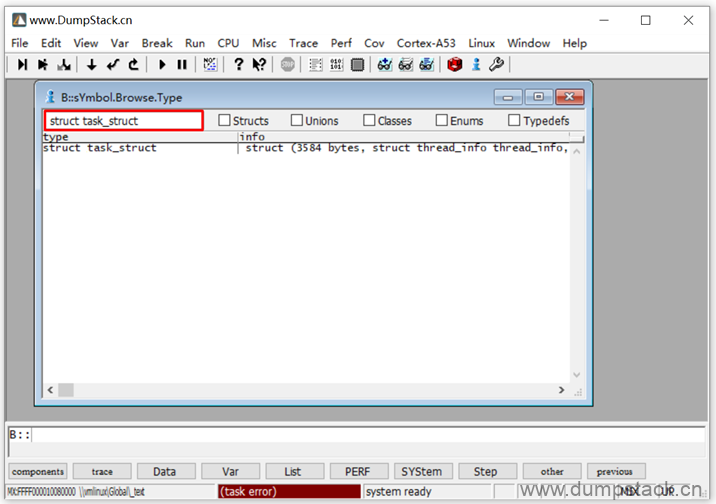
得到各个成员的偏移量如下:
3.5 实现container_of功能
例如我们现在知道一个任务的task_struct->sched_class的地址为0xFFFFFFE6F07BBED8,我们想要知道他的task_struct结构的地址,并且还想知道他的task_struct->comm名是啥
task_struct结构如下
| struct task_struct { ... const struct sched_class *sched_class; ... char comm[TASK_COMM_LEN]; ... } |
第一步:首先计算sched_class在task_struct结构中的偏移量,执行如下命令:
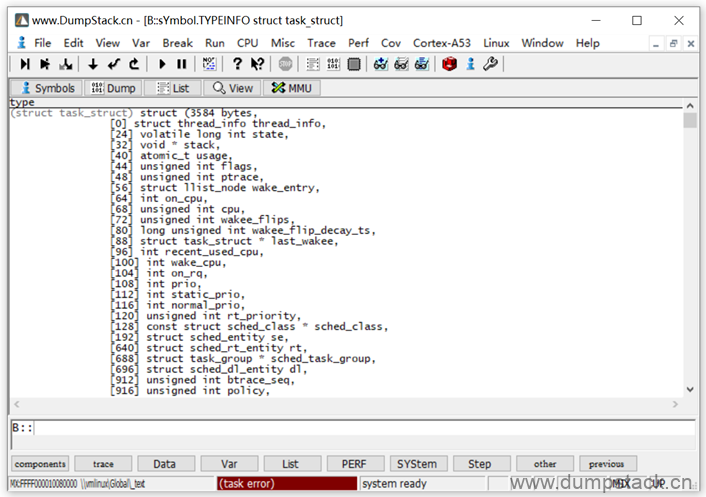
| Var.view &((struct task_struct *)0)->sched_class |
如下,得到偏移量为0x98
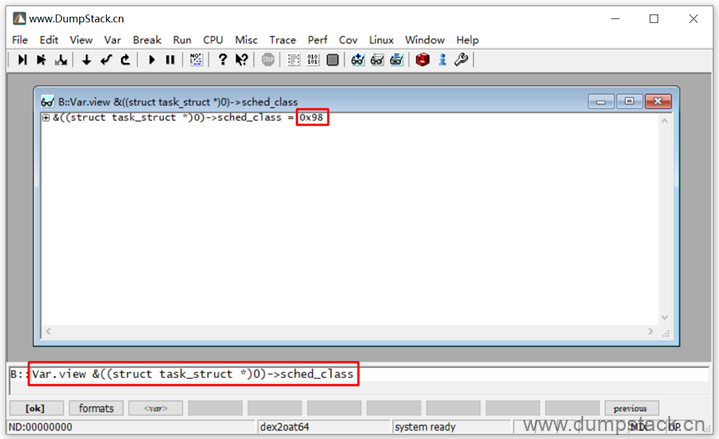
或者通过View -> Symbols -> Browse Types,直接查看这个数据类型,找到对于的成员对应的偏移量,如下
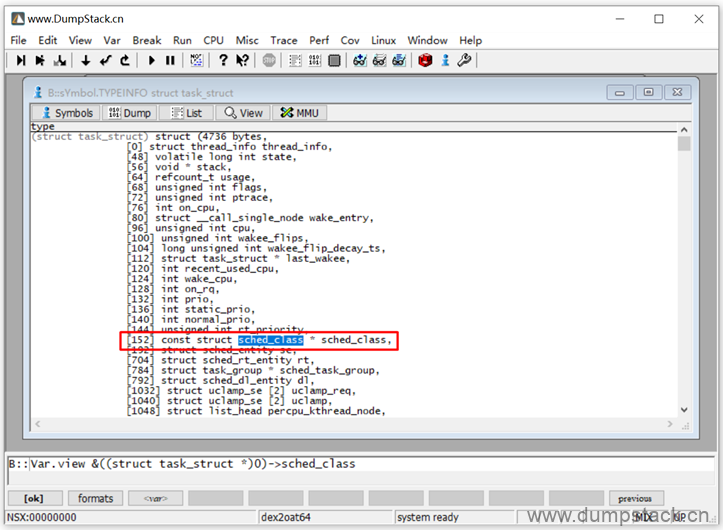
第二步:计算出task_struct结构的地址
task_struct->sched_class的地址为0xFFFFFFE6F07BBED8,sched_class在task_struct中的偏移量为0x98,则task_struct结构的地址应该为0xFFFFFFE6F07BBED8 - 0x98 = 0xFFFFFFE6F07BBE40
第三步:将指定的地址按照指定的格式显示
执行下面命令,将0xFFFFFFE6F07BBE40按照task_struct类型解析
| Var.view ((struct task_struct *)0xFFFFFFE6F07BBE40) |
解析结果如下:
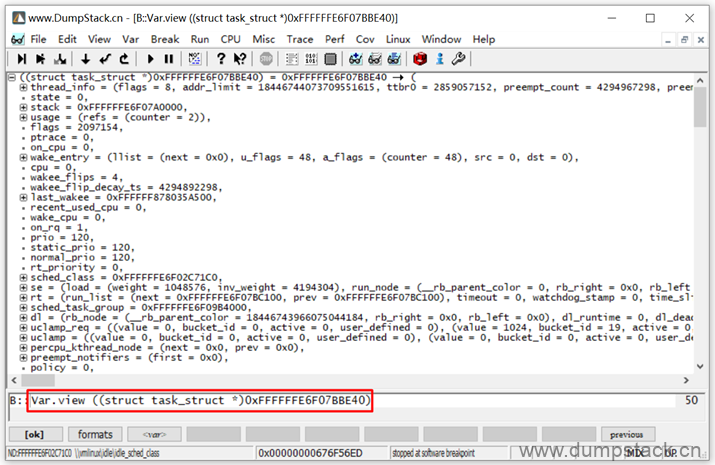
第四步:查看这个task的comm
直接Ctrl + F组合键搜索comm成员名称,如下:
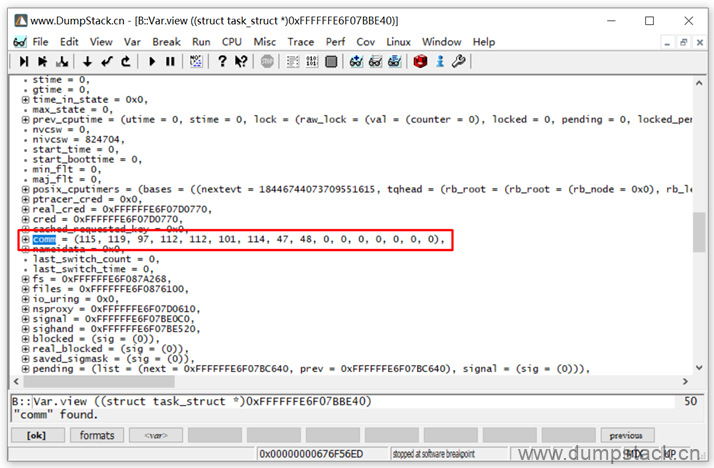
按字符串的格式显示:变量名上右键 -> Format在弹出的对话框中勾选Strings选项
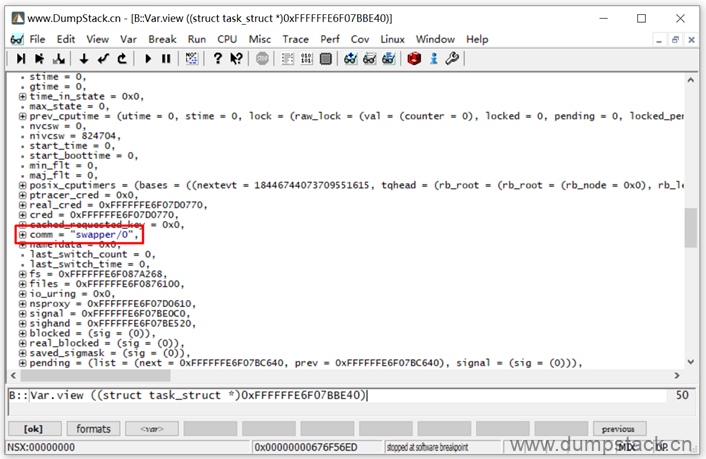
第五步:这个全局的task_struct对应的符号是啥,也就是说这个结构体的名字叫啥
有两个方法:变量名上右键 -> Display Memory -> Indirect View
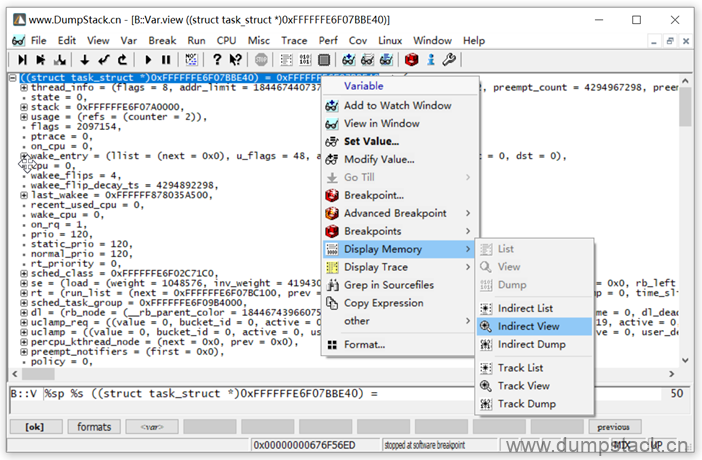
显示如下:
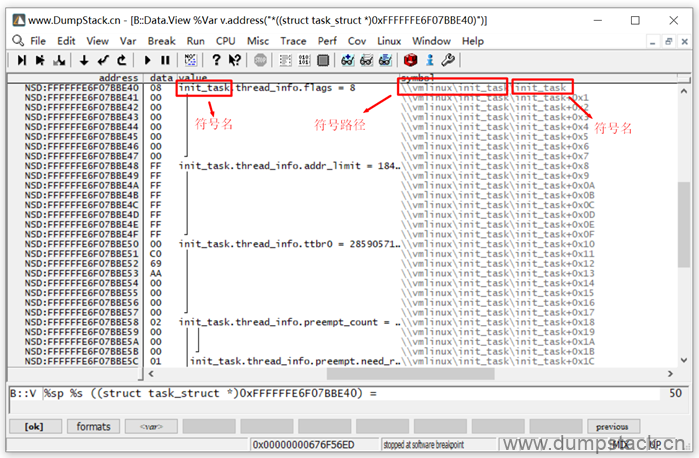
还有一个方法:
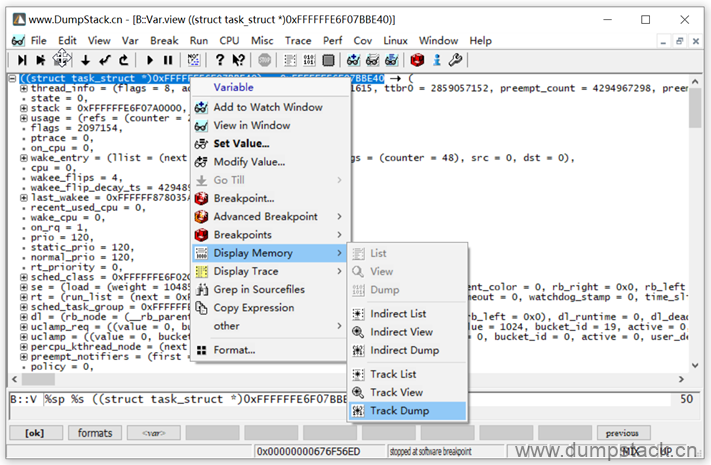
在变量名上右键 -> Dsaplay Memory -> Track Dump
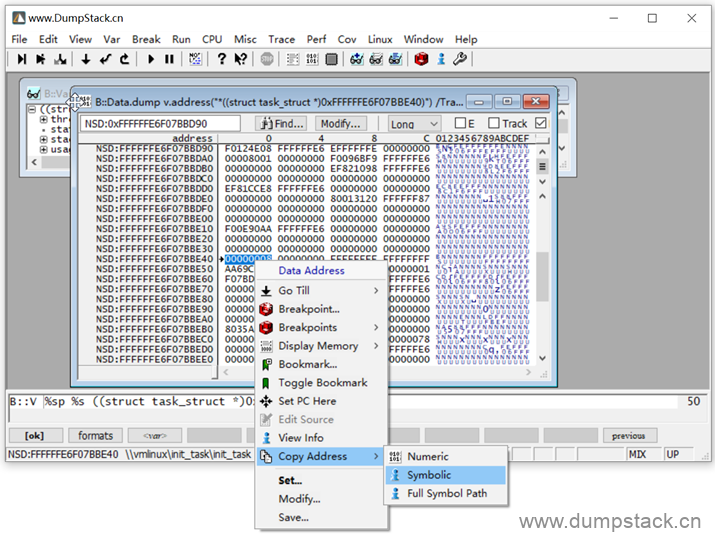
弹出下面内存视图,在指定的内存上右键 -> Copy Address -> Symbolic或者Full Symbol Path,就会将对应的符号名拷贝到剪切板,具体如下:
| Symbolic: init_task Full Symbol Path: \\vmlinux\init_task\init_task |
3.6 查看percpu变量
由percpu变量的实现原理可知,系统先申请一段连续的空间,平均分成N份,每个cpu对应一段独立的空间,每个cpu的percpu变量就放在这段连续的空间内,每个cpu对应的percpu空间相对于这段连续空间的偏移量记录在__per_cpu_offset[N]数组中,因此我们只要找到某个cpu的percpu变量,加上这段偏移量就能找到任意cpu上的percpu变量,下面举个例子
U:\linux-5.10.61\kernel\sched\sched.h
| DECLARE_PER_CPU_SHARED_ALIGNED(struct rq, runqueues); |
通过下面的方法获得runqueues变量的地址为0xFFFFFFE6F078BD00,注意这是cpu0的percpu变量
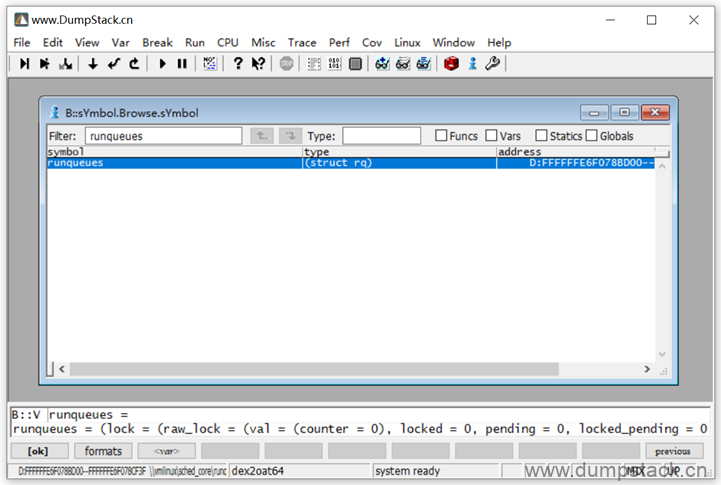
我们可以通过下面的方法获得cpu4上的percpu变量
| Var.View (struct rq*)(0xFFFFFFE6F078BD00 + __per_cpu_offset[4]) |
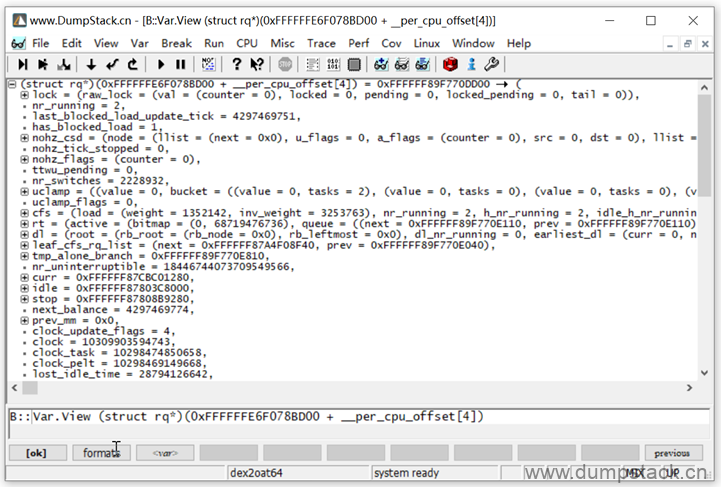
有时候上面的方法会失败,例如下面就是一个失败的案例,为啥捏?现在还没有搞明白,后面补充吧!
通过下面的方法找到cpu0的percpu变量的值为0xFFFFFFE6F078AA40
| static DEFINE_PER_CPU(struct cpufreq_policy *, cpufreq_cpu_data); |
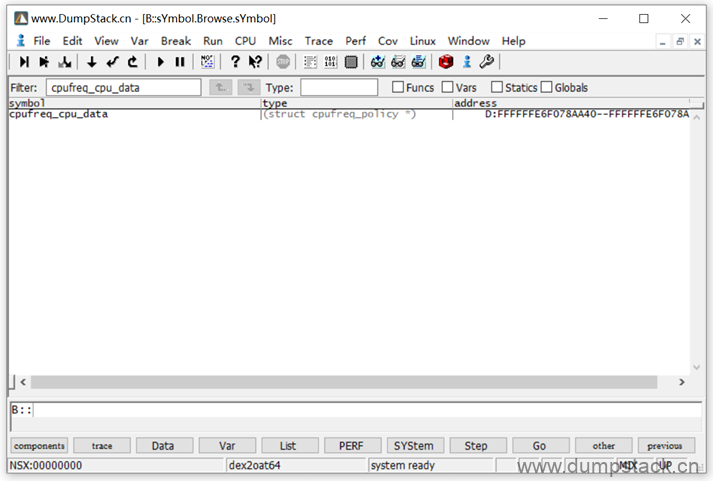
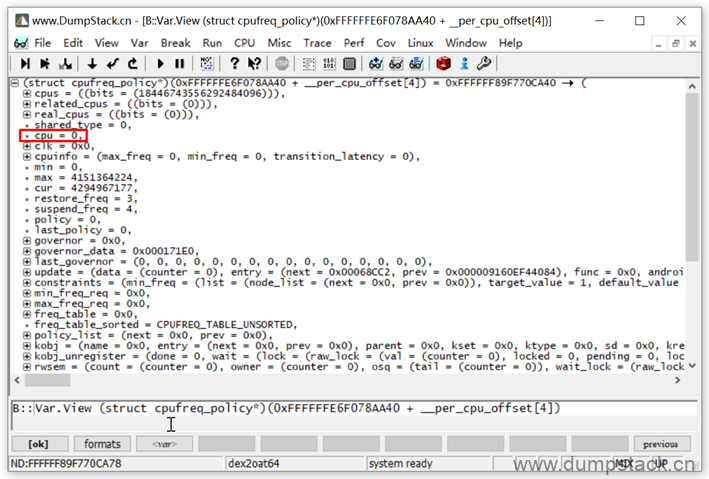
用下面命令虽然也找到了一个cpufreq_policy结构,但是从其成员cpu=0可知,这里找到的是不对的!为啥捏?
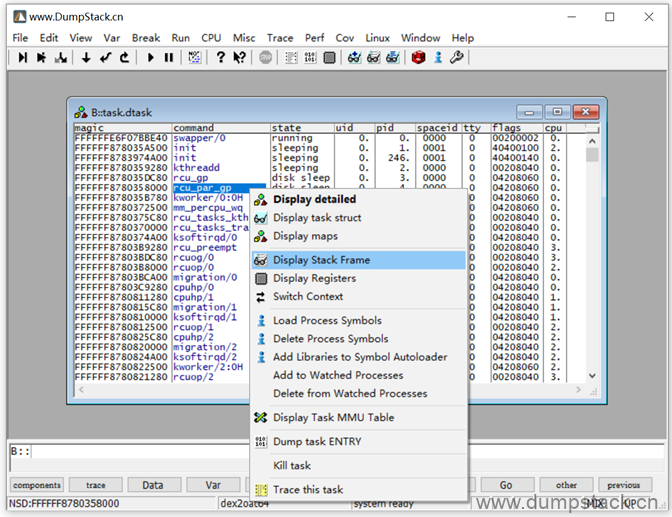
3.7 查看线程的调用栈
需要注意的是,查看线程的调用栈有两种情况:
一种是对非current线程的调用栈进行查看,这种线程的上下文(也就是线程执行时候的x0~x31寄存器的值)是保存在对应的task_struct结构的,这时候trace32恢复这个线程的上下文就能看到调用栈信息;
另一种是对current线程的调用栈进行查看,这种线程一般是cpu产生异常的那个时刻正在运行的线程,因为异常产生的太突然,线程的上下文(x0~x31寄存器的值)还没有保存进task_struct里面,机器就挂了,此时我们需要从dmesg中提取出各个寄存器的值,手动恢复到对应的寄存器中去
下面依次举例
3.7.1 查看非current线程的调用栈
下面我们就以rcu_par_gp线程为例,如下,在线程名上右键->Display Stack Frame就能查看对应的线程的调用栈
先查看这个线程的上下文,在线程名上右键->Display Registers
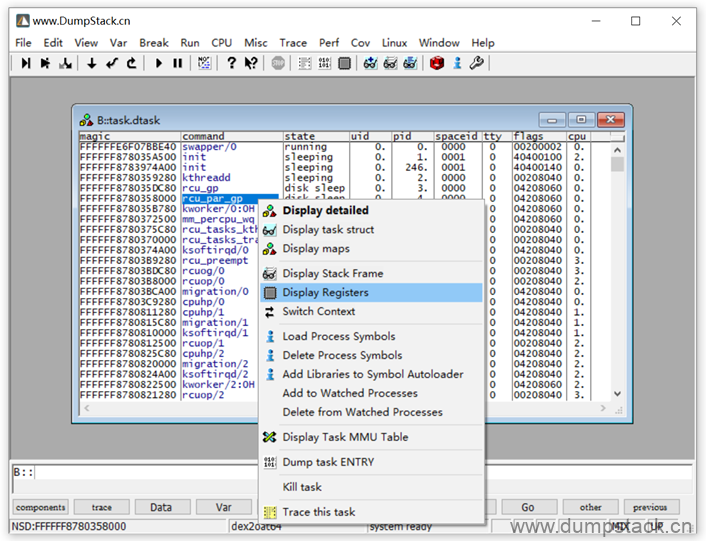
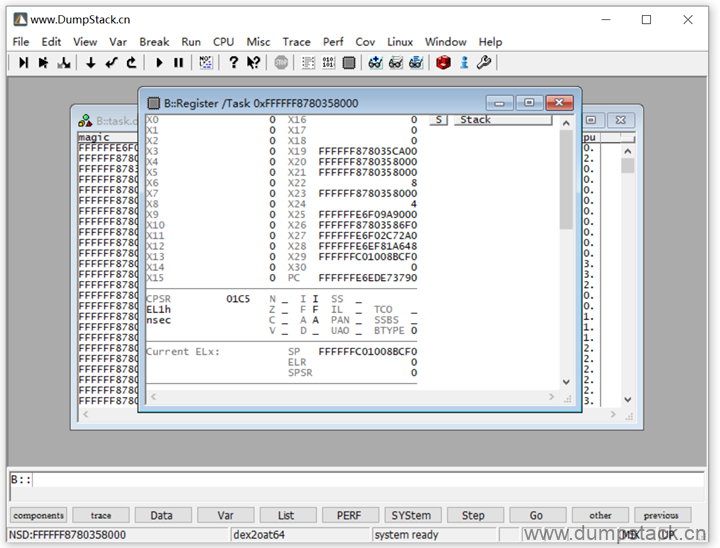
而此时的cpu的寄存器为全0,还不是在这个线程的上下文中
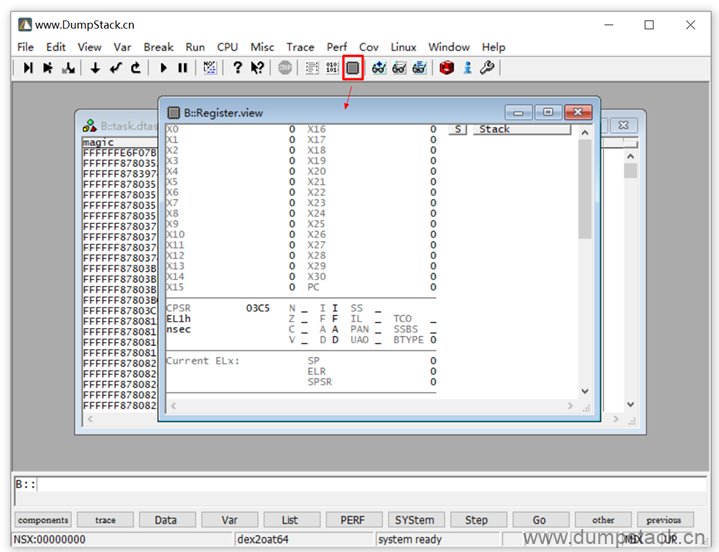
下面我们恢复指定线程的上下文:在线程名上右键->Switch Context
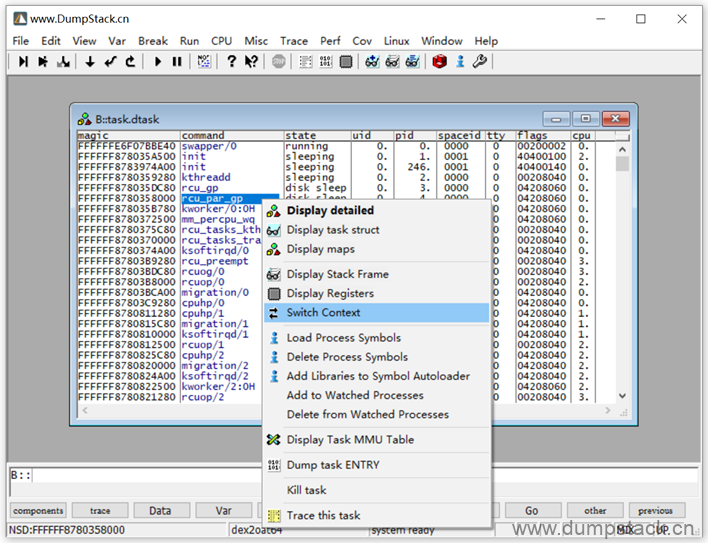
这时候我们再来看一下cpu的寄存器,就是这个线程的上下文了,右下角红框处标记当前所处的上下文
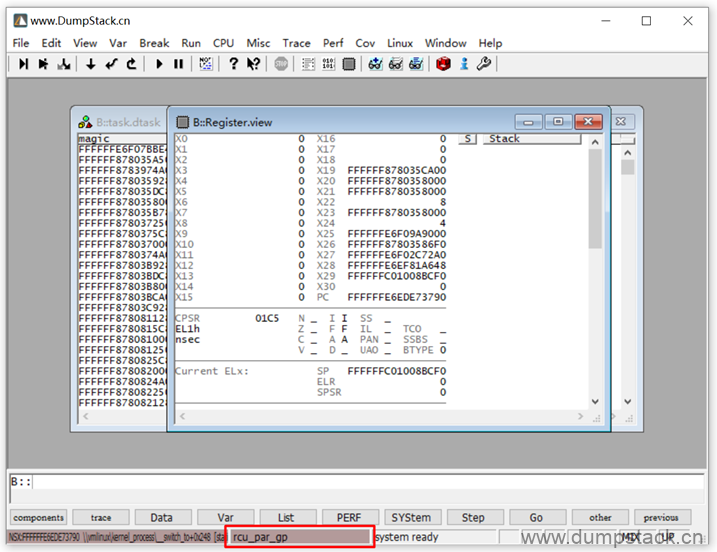
这时候我们再来查看线程的调用栈,如下:
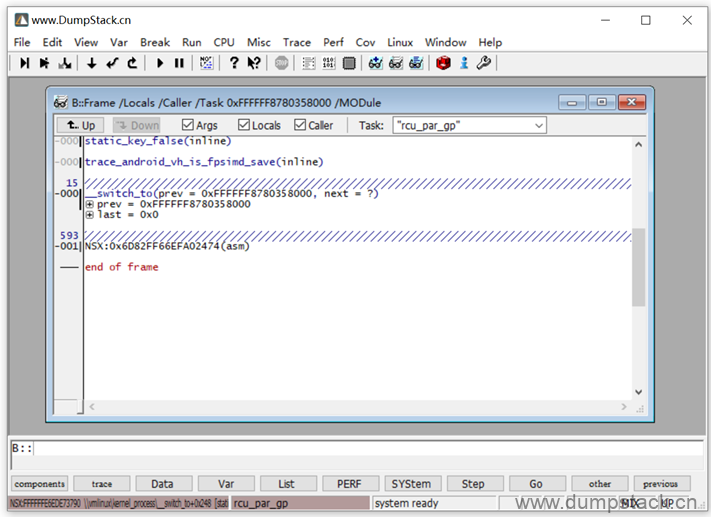
实际上这里显示的还是有问题的,因为我用的是armv9a的架构,在armv9a上支持PAC(pointer authentication of instruction address),关于PAC相关的feature,我们不在这里深究,但是我们可以通过ENIA寄存器关闭
通过CPU->Peripherals调出下面的片上外设的寄存器
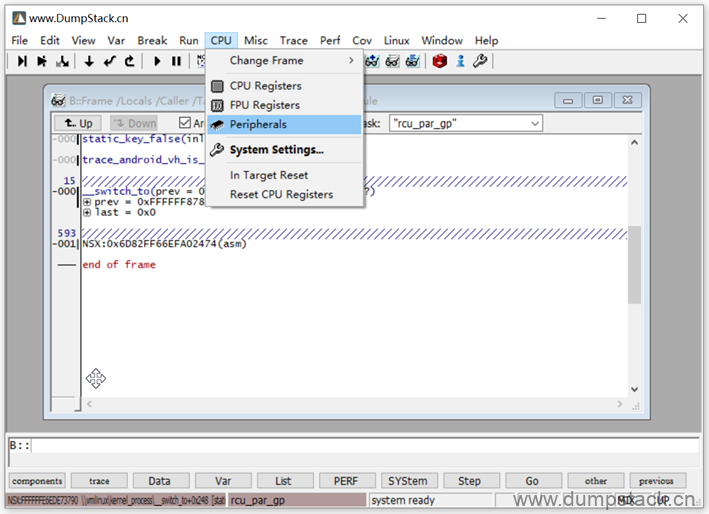
双击将下面的ENIA配置为Enable状态
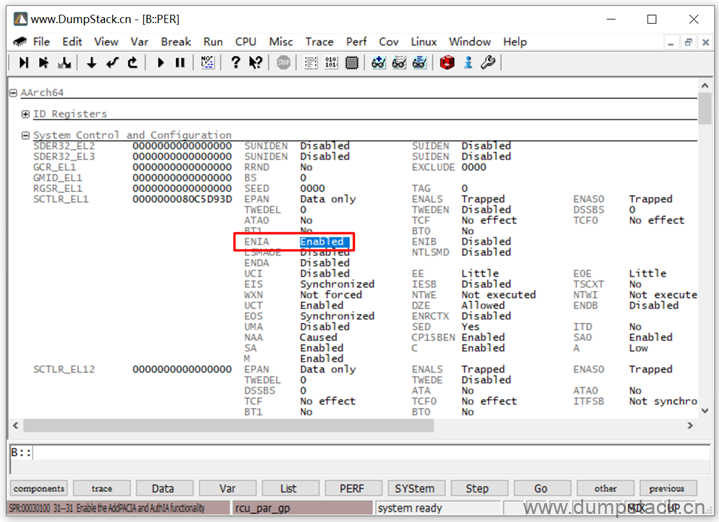
3.7.2 查看current线程的调用栈
下面我们查看current线程的调用栈,下面我们以这个sh线程为例,他跑在cpu3上
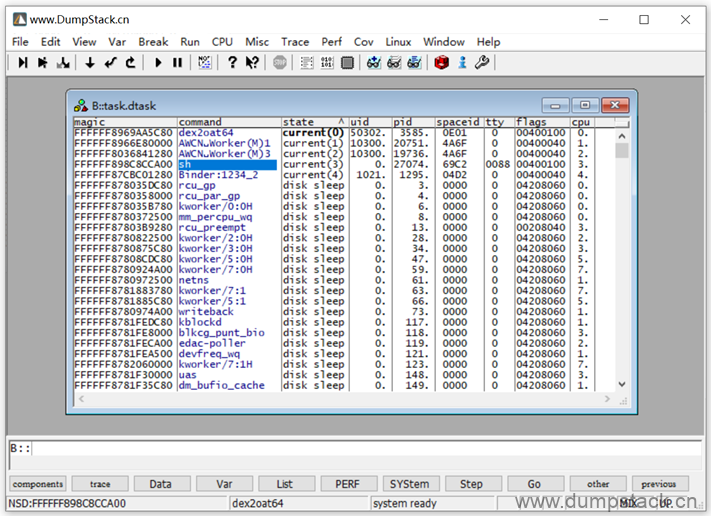
首先Switch Context切换到这个线程的上下文,然后看一下这个线程的上下文,如下:
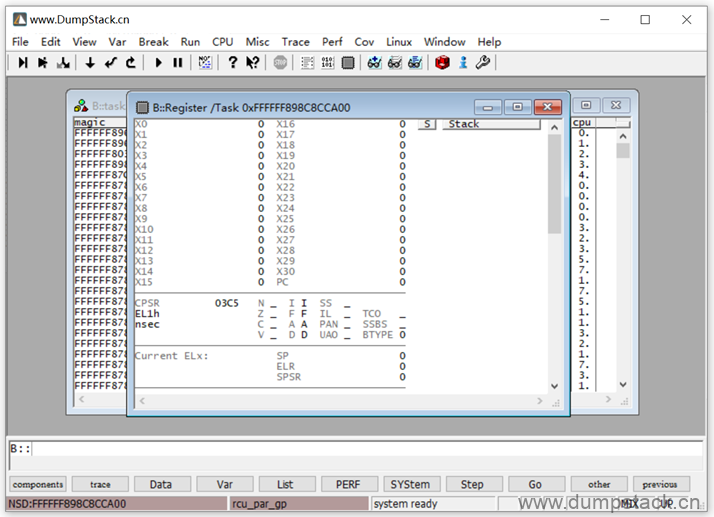
全部是0,这时候去查看调用栈是看不出的
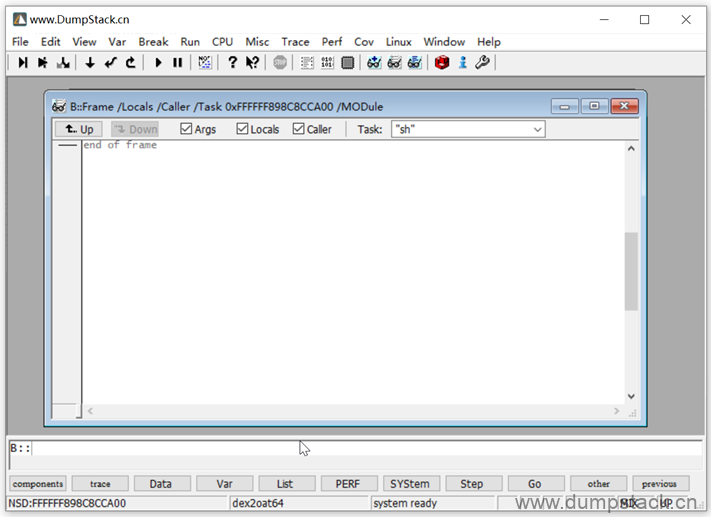
此时我们手动恢复这个线程的上下文
我们发现这个线程泡在cpu3上,我们从dmesg信息中提取出这个cpu的现场信息,如下
| [10309.903225][T27074] CPU: 3 PID: 27074 Comm: sh Tainted: G S W O 5.10.66-android12-9-00058-ga5bf636058a3-dirty #1 [10309.903232][T27074] Hardware name: Qualcomm Technologies, Inc. Waipio MTP with PM8010, baize (DT) [10309.903242][T27074] pstate: 62400005 (nZCv daif +PAN -UAO +TCO BTYPE=--) [10309.903271][T27074] pc : jank_unit_test+0x308/0x344 [cpu_jankinfo] [10309.903293][T27074] lr : jank_unit_test+0x84/0x344 [cpu_jankinfo] [10309.903299][T27074] sp : ffffffc0627a3b10 [10309.903306][T27074] x29: ffffffc0627a3b50 x28: ffffff898c8cca00 [10309.903316][T27074] x27: 0000000000000000 x26: 0000000000000000 [10309.903326][T27074] x25: 0000000000000000 x24: ffffff89e88e1838 [10309.903336][T27074] x23: ffffff898c8cca00 x22: b40000771222e1e8 [10309.903346][T27074] x21: 0000000000000001 x20: ffffffe6ea2e1081 [10309.903355][T27074] x19: ffffffc0627a3b1c x18: ffffffc037ec5048 [10309.903365][T27074] x17: 0000000000000000 x16: 0000000000000000 [10309.903375][T27074] x15: 0000000000000000 x14: 00000000ffffffbf [10309.903385][T27074] x13: 0000000000000020 x12: ffffffc0627a3ba9 [10309.903394][T27074] x11: 0000000000000250 x10: ffffffe6ea2dfa68 [10309.903404][T27074] x9 : ffffffe6ea2e1000 x8 : 0000000000000008 [10309.903413][T27074] x7 : fefefefefefefefe x6 : 0000808080808080 [10309.903423][T27074] x5 : 0000000000000000 x4 : ffffffffffffffff [10309.903432][T27074] x3 : 0000000000000a36 x2 : ffffffc0627a3ae0 [10309.903442][T27074] x1 : ffffffe6ea2e1081 x0 : 0000000000000000 |
从中提取出各个寄存器的值如下:
| pc : jank_unit_test+0x308/0x344 [cpu_jankinfo] lr : jank_unit_test+0x84/0x344 [cpu_jankinfo] sp : ffffffc0627a3b10 x29: ffffffc0627a3b50 x28: ffffff898c8cca00 x27: 0000000000000000 x26: 0000000000000000 x25: 0000000000000000 x24: ffffff89e88e1838 x23: ffffff898c8cca00 x22: b40000771222e1e8 x21: 0000000000000001 x20: ffffffe6ea2e1081 x19: ffffffc0627a3b1c x18: ffffffc037ec5048 x17: 0000000000000000 x16: 0000000000000000 x15: 0000000000000000 x14: 00000000ffffffbf x13: 0000000000000020 x12: ffffffc0627a3ba9 x11: 0000000000000250 x10: ffffffe6ea2dfa68 x9 : ffffffe6ea2e1000 x8 : 0000000000000008 x7 : fefefefefefefefe x6 : 0000808080808080 x5 : 0000000000000000 x4 : ffffffffffffffff x3 : 0000000000000a36 x2 : ffffffc0627a3ae0 x1 : ffffffe6ea2e1081 x0 : 0000000000000000 |
由上面可知pc和lr当前所指向的区域在一个驱动ko里面,所以首先我们要先加载这个ko,如下,打开Linux标签 -> Module Debugging -> Load Symbols,选择要load的ko文件
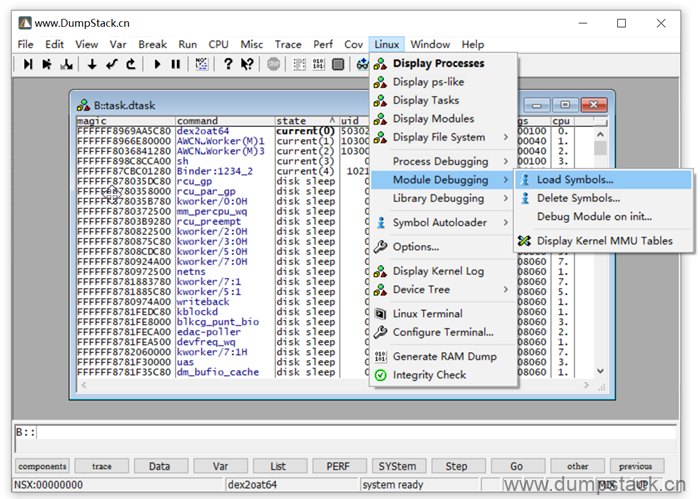
ko加载后我们就能找到ko中的符号了,如下:
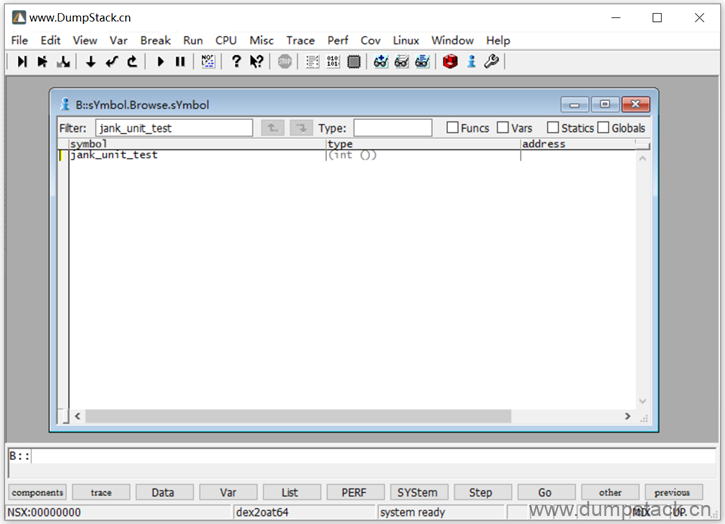
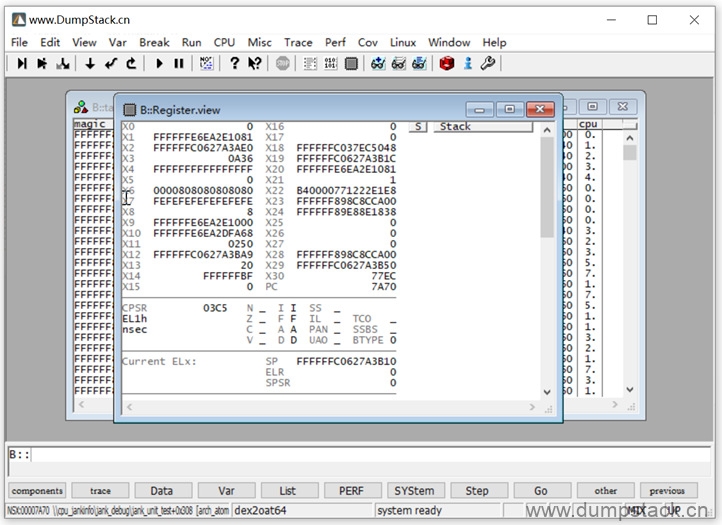
此时我们就得到了这个current线程的上下文,如下,保存为cmm脚本并执行
| CORE.select 3 r.s pc jank_unit_test+0x308 r.s lr jank_unit_test+0x84 r.s sp 0xffffffc0627a3b10 r.s x29 0xffffffc0627a3b50 r.s x28 0xffffff898c8cca00 r.s x27 0x0000000000000000 r.s x26 0x0000000000000000 r.s x25 0x0000000000000000 r.s x24 0xffffff89e88e1838 r.s x23 0xffffff898c8cca00 r.s x22 0xb40000771222e1e8 r.s x21 0x0000000000000001 r.s x20 0xffffffe6ea2e1081 r.s x19 0xffffffc0627a3b1c r.s x18 0xffffffc037ec5048 r.s x17 0x0000000000000000 r.s x16 0x0000000000000000 r.s x15 0x0000000000000000 r.s x14 0x00000000ffffffbf r.s x13 0x0000000000000020 r.s x12 0xffffffc0627a3ba9 r.s x11 0x0000000000000250 r.s x10 0xffffffe6ea2dfa68 r.s x9 0xffffffe6ea2e1000 r.s x8 0x0000000000000008 r.s x7 0xfefefefefefefefe r.s x6 0x0000808080808080 r.s x5 0x0000000000000000 r.s x4 0xffffffffffffffff r.s x3 0x0000000000000a36 r.s x2 0xffffffc0627a3ae0 r.s x1 0xffffffe6ea2e1081 r.s x0 0x0000000000000000 |
执行完毕后再看cpu寄存器,如下:
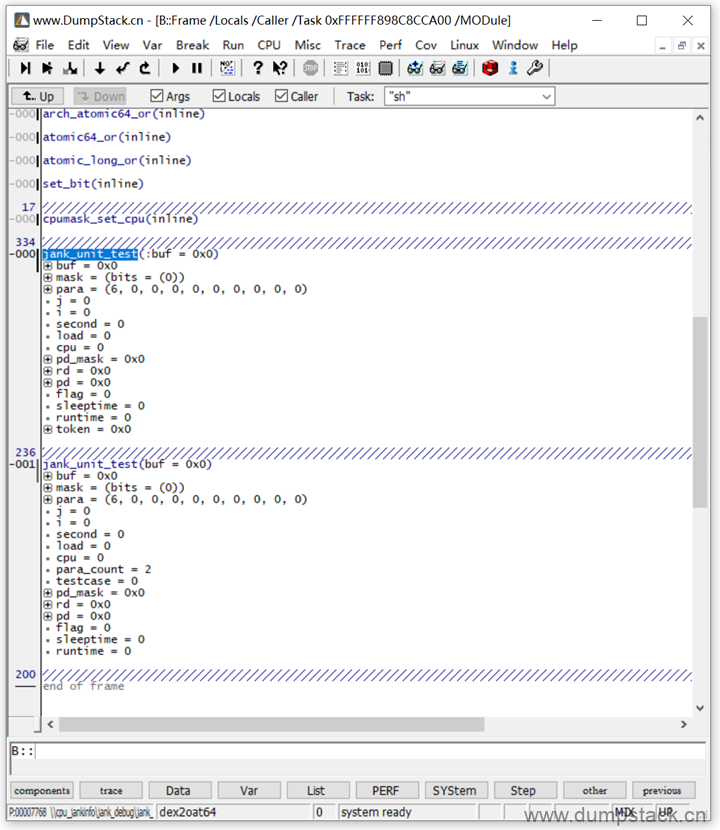
此时再来看这个线程的调用栈信息,如下
3.8 查看用户空间进程的调用栈信息
参考文章如下,我的是arm64的,不知道为什么操作不了,可能是一些系统寄存器配置的不对,先不管了,直接搬移过来了
https://www.cnblogs.com/DF11G/p/14511466.html
一般情况下我们加载dump或者在线attach时只加载了Kernel的符号表(vmlinux),此时只能看到内核空间的调用栈关系,如下图:


如果想显示用户空间的调用栈关系,可以这么做:
(1)点开菜单Linux->Display Processes,在任务列表里面找到当前的任务,点击右键选择Display Detailed,打开如下窗口:
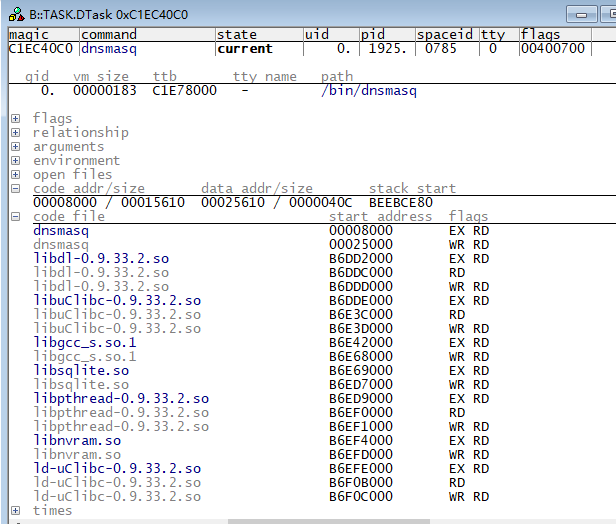
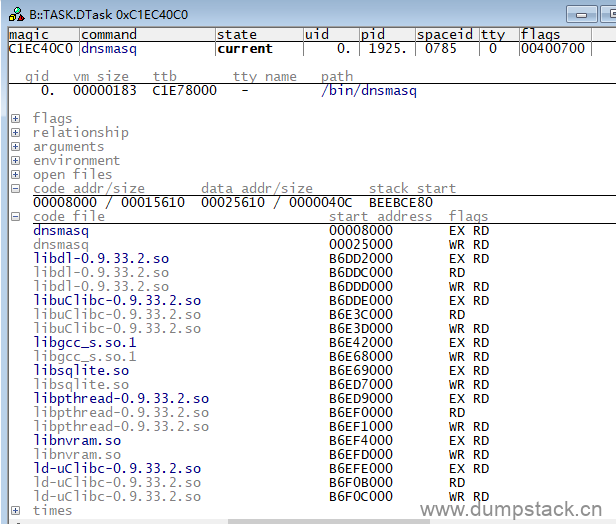
(2)在code file选项卡中可以看到:libuClibc的开始地址为0xb6dde000,其它库文件的地址也都一起列了出来;
(3)加载dnsmasq主进程符号表与libuClibc的符号表
| //注意:dnsmasq.elf文件编译时已包含偏移地址0x8000,此时不需要再指定偏移 data.load.elf E:\RD\Trace32\0511\dnsmasq.elf /nocode /noclear //so文件为使用uClibc-0.9.33.2进行交叉编译后得到的elf文件 data.load.elf E:\RD\Trace32\0511\libuClibc-0.9.33.2.so 0xb6dde000 /nocode /noclear |
(4)一般情况下加载上面两项后即可以看到用户进程的调用栈关系,如果有的地址还是无法解析,可以进一步加载对应地址的库文件的符号表。
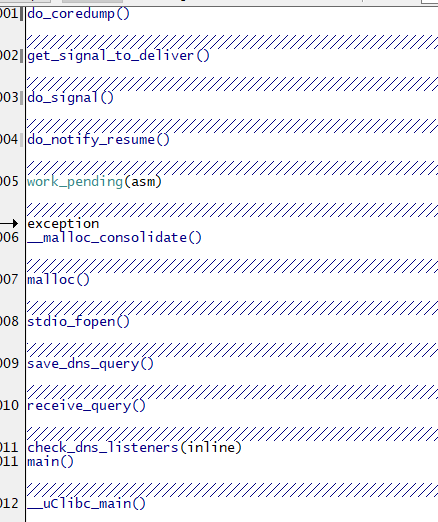
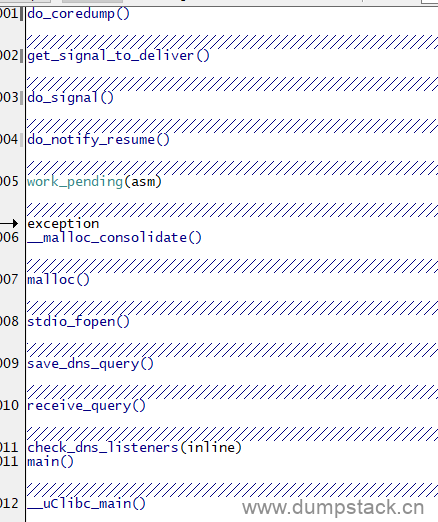
3.9 查看任意进程的调用栈
一般情况下我们加载dump或者在线attach后只能看到当前用户进程的调用栈信息,如果想看其他任务的调用栈关系,可以这么做:
(1)点开菜单Linux->Display Processes,在任务列表里面找到当前的任务,点击右键选择Display Task Struct,打开如下窗口:
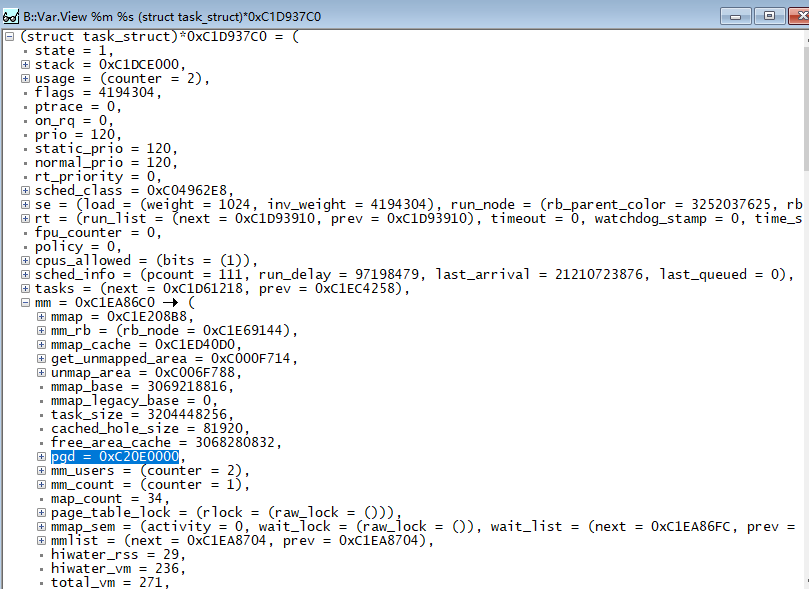
(2)读取该进程的一级页表基地址即PGD,具体路径为(task_struct)->mm->pgd,得到PGD的虚拟地址;
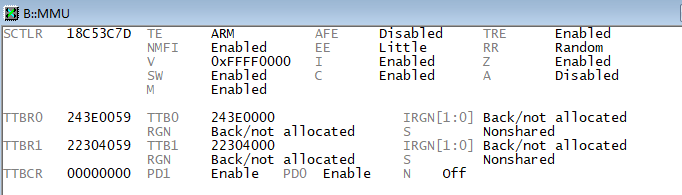
(3)根据内核空间虚拟地址和物理地址的映射关系,将PGD转换为物理地址,例如映射关系为(0xc0000000<-->0x22300000),那么该PGD的物理地址为0x243e0000
(4)将转换后的PGD物理地址写入TTBR0的基地址段([31:10]):

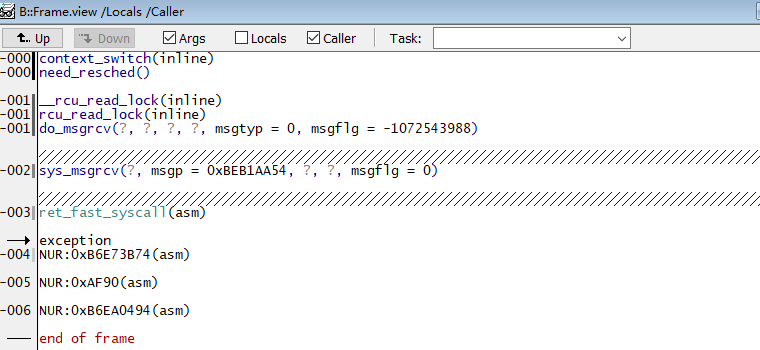
(5)回到第一步的任务列表,右键点击要切换的目的任务,选择Switch Context,此时就能看到该任务的调用栈关系:
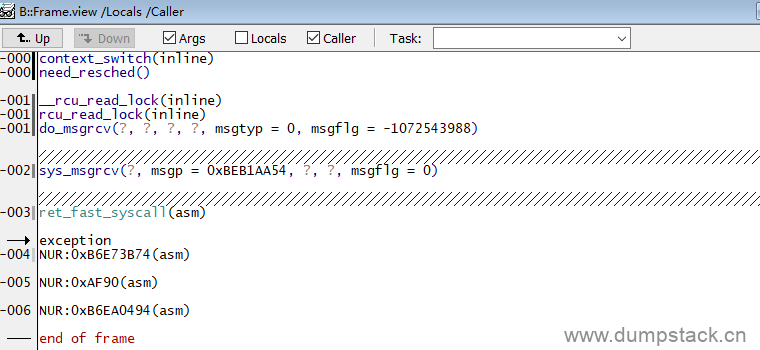
(6)如果还要进一步查看用户空间的调用栈关系,可以继续按照上一章的的方法进行实现
3.10 找到异常线程
第一步:定位异常产生时的线程
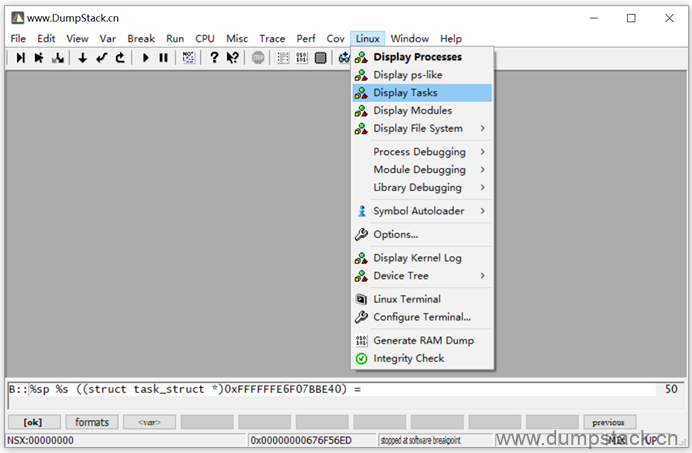
查看产生crash时正在运行那个任务:linux -> Display Tasks
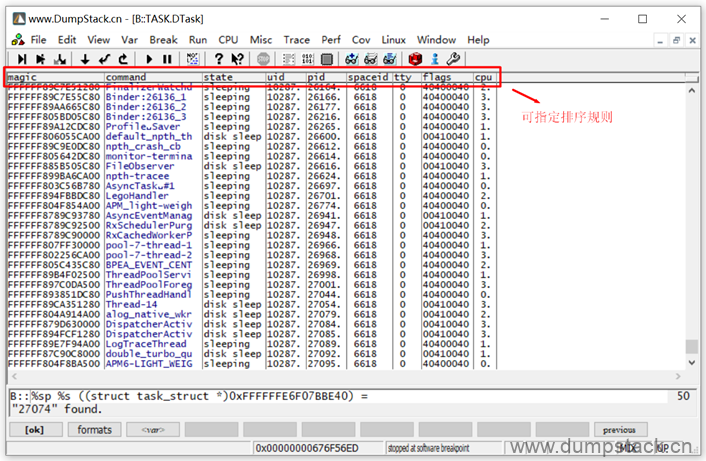
视图如下,通过最上面的标签,可以指定排序规则,你也可以在这个视图中Ctrl + F快速找到指定的pid任务
通过对state进行排序,可以快速找到crash时,cpu上正在运行哪些线程
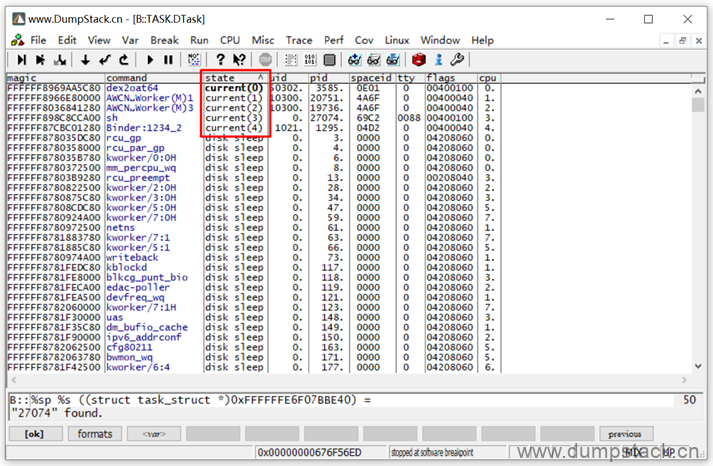
但是当有多个cpu时,不能确定到底是那个cpu上的current导致的crash,此时需要结合dmesg信息,如下示例,可以判断异常线程是cpu3上的current
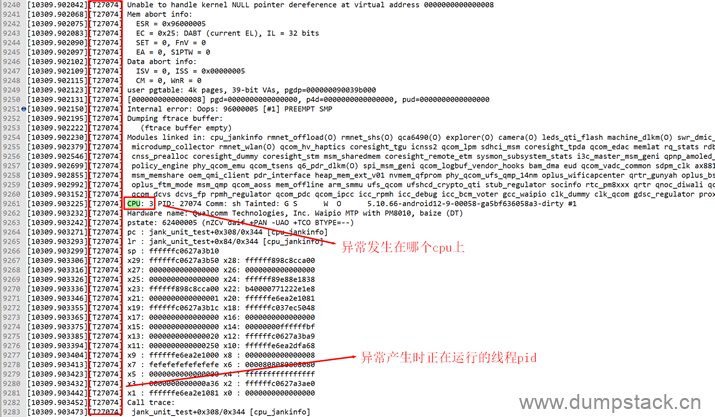
另一方面,从上面的dmesg日志,还能得到crash产生时的线程pid,我们通过ctrl+F来查看这个线程,如下
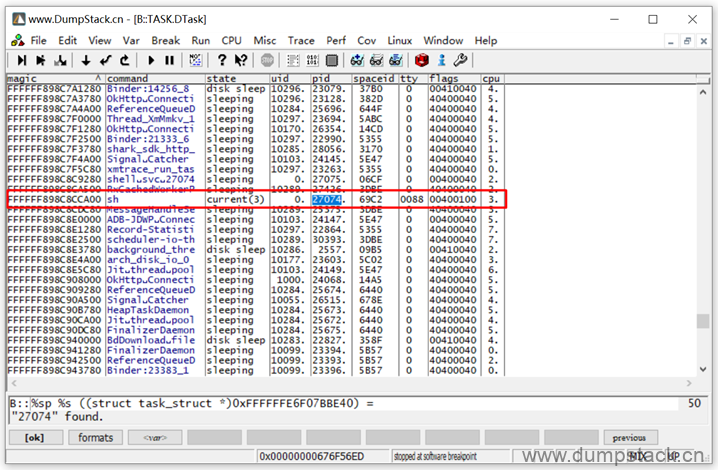
第二步:查看异常线程的调用栈
在指定的线程上右键,可以查看更多的细节(Display detailed,双击也能可以实现该功能),或者查看这个task对应的task_struct结构(Display task struct)
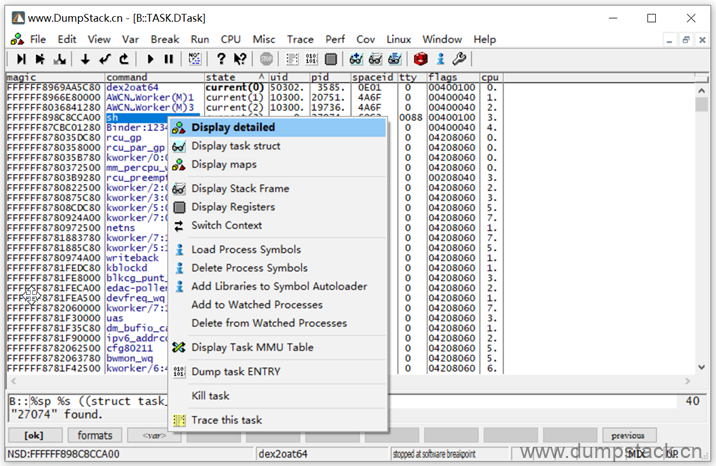
下面我们双击线程查看更多细节,如下:
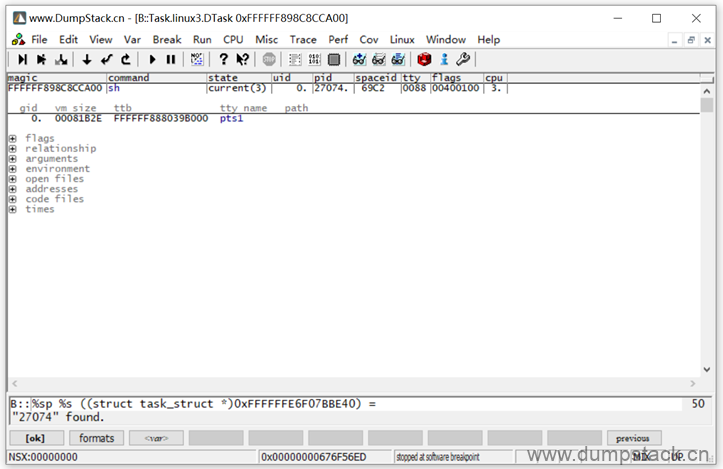
各项展开如下:
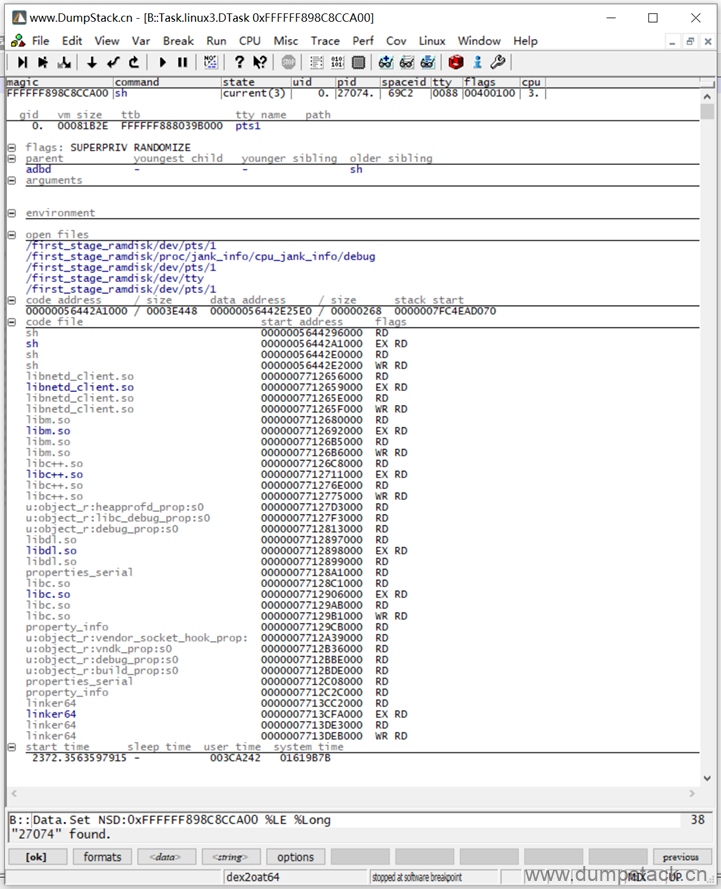
各个参数含义如下:
-
flags

-
relationship

-
arguments
暂时不知道作用
-
environment
暂时不知道作用
-
open files
打开了哪些文件

-
addresses

-
code files
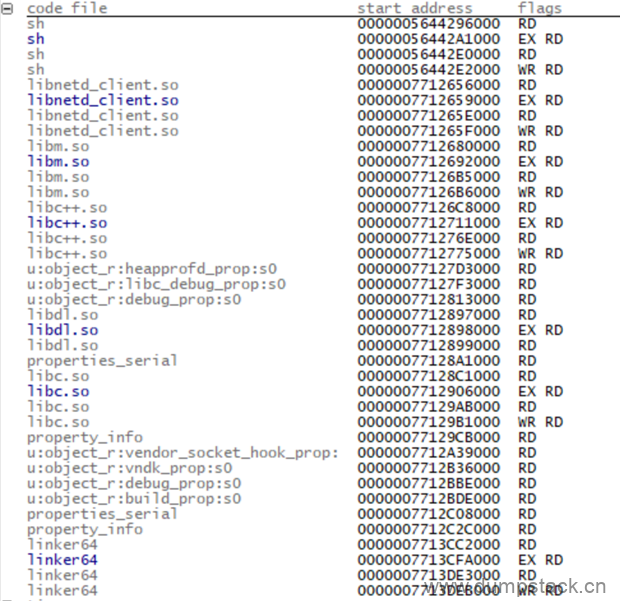
-
times
记录这个线程在什么时候创建的、什么时候结束的、处于用户空间和内核空间的时间
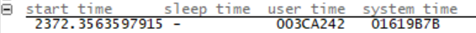
四、案例分析
案例来源:
https://blog.csdn.net/forever_2015/article/details/77434580
导致panic的源码改动是同一处,但是死机后的表现却可能大不一样,像这个问题当时出现的时候抓两份ramdump,解开后却发现表现不一样(很可能每次出现死机都在不一样的地方),逆向推导过程总是需要耐心细心分析,加上一定的运气成分,下面举个例子
dmesg信息如下:
| [ 256.595276] list_add corruption. prev->next should be next (ffffffc0ab1d4178), but was ffffffc0aba4c628. (prev=ffffffc001b77da8). [ 256.595282] Modules linked in: wlan(O) [ 256.595299] CPU: 5 PID: 6210 Comm: mdss_fb0 Tainted: G W O 3.18.31 #1 [ 256.595305] Hardware name: Qualcomm Technologies, Inc. MSM8940-PMI8950 MTP (DT) [ 256.595311] Call trace: [ 256.595324] [<ffffffc000089b14>] dump_backtrace+0x0/0x270 [ 256.595334] [<ffffffc000089d98>] show_stack+0x14/0x1c [ 256.595345] [<ffffffc000dbd254>] dump_stack+0x80/0xa4 [ 256.595356] [<ffffffc0000a3240>] warn_slowpath_common+0x8c/0xb0 [ 256.595366] [<ffffffc0000a32c4>] warn_slowpath_fmt+0x60/0x80 [ 256.595374] [<ffffffc000345dd4>] __list_add+0x74/0xf0 [ 256.595384] [<ffffffc00010356c>] __internal_add_timer+0xb4/0xbc [ 256.595392] [<ffffffc000103b30>] internal_add_timer+0x34/0x90 [ 256.595404] [<ffffffc000dca78c>] schedule_timeout+0x1f0/0x278 [ 256.595414] [<ffffffc0003e95f0>] mdss_mdp_cmd_wait4pingpong+0x12c/0x534 [ 256.595424] [<ffffffc0003c1494>] mdss_mdp_display_wait4pingpong+0xd8/0x404 [ 256.595432] [<ffffffc0003c2110>] mdss_mdp_display_commit+0x890/0x1128 [ 256.595443] [<ffffffc0003f8c30>] mdss_mdp_overlay_kickoff+0x9ec/0x15f4 [ 256.595453] [<ffffffc00043e098>] __mdss_fb_display_thread+0x278/0x4c4 [ 256.595462] [<ffffffc0000beccc>] kthread+0xf0/0xf8 [ 256.595468] ---[ end trace 02fd337171f1bd82 ]--- [ 256.595498] ------------[ cut here ]------------ [ 256.595506] kernel BUG at /home/android/work/prj/6901-7.1/LA.UM.5.6/LINUX/android/kernel/msm-3.18/lib/list_debug.c:40! [ 256.595513] Internal error: Oops - BUG: 0 [#1] PREEMPT SMP [ 256.595519] Modules linked in: wlan(O) [ 256.595533] CPU: 5 PID: 6210 Comm: mdss_fb0 Tainted: G W O 3.18.31 #1 [ 256.595538] Hardware name: Qualcomm Technologies, Inc. MSM8940-PMI8950 MTP (DT) [ 256.595545] task: ffffffc02f5e6e00 ti: ffffffc002bdc000 task.ti: ffffffc002bdc000 [ 256.595553] PC is at __list_add+0xcc/0xf0 [ 256.595560] LR is at __list_add+0x74/0xf0 [ 256.595567] pc : [<ffffffc000345e2c>] lr : [<ffffffc000345dd4>] pstate: 200001c5 ... |
看到kernel BUG我们就知道,这个属于内核主动上报异常的行为,我们看看list_debug.c:40这里有什么?
__list_add是在prev和next之间插入new,上面打印的kernel BUG明显就是触发了BUG_ON(x)的条件导致
| void __list_add(struct list_head *new, struct list_head *prev, struct list_head *next) { WARN(next->prev != prev, "list_add corruption. next->prev should be " "prev (%p), but was %p. (next=%p).\n", prev, next->prev, next); WARN(prev->next != next, "list_add corruption. prev->next should be " "next (%p), but was %p. (prev=%p).\n", next, prev->next, prev); WARN(new == prev || new == next, "list_add double add: new=%p, prev=%p, next=%p.\n", new, prev, next); BUG_ON((prev->next != next || next->prev != prev || new == prev || new == next) && PANIC_CORRUPTION); next->prev = new; new->next = next; new->prev = prev; prev->next = new; } |
这个内核双链表标准的插入实现,这个BUG_ON条件满足被触发了Panic所致,表示参数传的有错误。继续看log发现:
| [ 256.595299] CPU: 5 PID: 6210 Comm: mdss_fb0 Tainted: G W O 3.18.31 #1 |
异常发生在CPU5这个核,线程名是mdss_fb0,这个是属于显示相关的进程,一般我们是动不到的,初步判断是别的地方改动埋的雷导致mdss_fb0在执行的时候出现异常,那么我们要做的就是如何根据这个异常现场找到埋雷的地方
打开Trace32,输入v.f回车,查看内核调用栈,如下:
| -000|ipi_cpu_stop(inline) -000|handle_IPI(ipinr = 3, regs = 0xFFFFFFC0A3BF36E0) -001|gic_handle_irq(regs = 0xFFFFFFC0A3BF36E0) -002|el1_irq(asm) -->|exception -003|debug_check_no_obj_freed(address = 0xFFFFFFC028805C00, size = 128) -004|current_thread_info(inline) -004|preempt_count(inline) -004|should_resched(inline) -004|slab_free(inline) -004|kfree(x = 0xFFFFFFC028805C00) -005|ext4_ext_map_blocks(handle = 0x0, inode = 0xFFFFFFC0A3FA8D50, map = 0xFFFFFFC0A3BF3A80, ?) -006|ext4_map_blocks(handle = 0x0, inode = 0x80, map = 0xFFFFFFC0A3BF3A80, flags = 12) -007|ext4_get_block(inode = 0xFFFFFFC0A3FA8D50, ?, bh = 0xFFFFFFC0A3BF3AD0, flags = 0) -008|ext4_get_block(?, ?, ?, ?) -009|generic_block_bmap(?, ?, ?) -010|ext4_bmap(mapping = 0xFFFFFFC0A3FA8ED0, block = 12712) -011|bmap(?, block = 128) -012|jbd2_journal_bmap(journal = 0xFFFFFFC0A41F3900, ?, retp = 0xFFFFFFC0A3BF3CC0) -013|jbd2_journal_next_log_block(journal = 0xFFFFFFC0A41F3900, retp = 0xFFFFFFC0A3BF3CC0) -014|jbd2_journal_commit_transaction(journal = 0xFFFFFFC0A41F3900) -015|kjournald2(arg = 0xFFFFFFC0A41F3900) -016|kthread(_create = 0xFFFFFFC0A41E4400) -017|ret_from_fork(asm) ---|end of frame |
这个调用看上去还挺正常的,属于正常的系统异常切换操作,并且,怎么发现跟dmesg里面看到的调用栈对不上呢?
我们来看下加载脚本:t32_startup_script.cmm
| title "/home/android/crash/Port_COM29-0813/out" sys.cpu CORTEXA53 sys.up data.load.binary /home/android/crash/Port_COM29-0813/OCIMEM.BIN 0x8600000 data.load.binary /home/android/crash/Port_COM29-0813/DDRCS0.BIN 0x40000000 data.load.binary /home/android/crash/Port_COM29-0813/DDRCS1.BIN 0x80000000 Register.Set NS 1 Data.Set SPR:0x30201 %Quad 0x41c22000 Data.Set SPR:0x30202 %Quad 0x00000032B5193519 Data.Set SPR:0x30A20 %Quad 0x000000FF440C0400 Data.Set SPR:0x30A30 %Quad 0x0000000000000000 Data.Set SPR:0x30100 %Quad 0x0000000004C5D93D Register.Set CPSR 0x3C5 MMU.Delete MMU.SCAN PT 0xFFFFFF8000000000--0xFFFFFFFFFFFFFFFF mmu.on mmu.pt.list 0xffffff8000000000 data.load.elf /home/android/crash/Port_COM29-0813/vmlinux /nocode task.config /opt/t32/demo/arm64/kernel/linux/linux-3.x/linux3.t32 menu.reprogram /opt/t32/demo/arm64/kernel/linux/linux-3.x/linux.men task.dtask v.v %ASCII %STRING linux_banner do /home/android/crash/Port_COM29-0813/out/core0_regs.cmm |
从上面可以看到脚本里面配置trace32默认加载的是CPU0的上下文,而我们从dmesg看到的panic异常是发生在CPU5,所以我们需要手动切换到CPU5的上下文,执行下面命令
PS: 这里有必要需要说明一下,按一般理解应该执行do core5_xx,但是我发现这样还不对,只能一个个试验了,发现刚好是core1的这个,暂时不知道具体原因
| do core1_regs.cmm |
得到小面的调用栈:
| -000|arch_counter_get_cntvct_cp15() -001|arch_counter_get_cntvct() -002|__delay(cycles = 19200) -003|__const_udelay(?) -004|msm_trigger_wdog_bite() -005|do_msm_restart(?, cmd = 0x0) -006|machine_restart(?) -007|emergency_restart() -008|panic(?) -009|oops_end(inline) -009|die(?, regs = 0xFFFFFFC002BDF870, err = 0) -010|arm64_notify_die(?, ?, ?, ?) -011|do_undefinstr(regs = 0xFFFFFFC002BDF870) --- 发生未定义指令异常 BUG() -012|__list_add(new = 0xFFFFFFC002BDF990, prev = 0xFFFFFFC001B77DA8, next = 0xFFFFFFC0AB1D4178) -013|__internal_add_timer(?, ?) -014|tbase_get_deferrable(inline) -014|internal_add_timer(base = 0xFFFFFFC0AB1D4000, timer = 0x0124F800) -015|spin_unlock_irqrestore(inline) -015|__mod_timer(inline) -015|schedule_timeout(?) -016|mdss_mdp_cmd_wait4pingpong(ctl = 0xFFFFFFC0A791A318, ?) -017|mdss_mdp_display_wait4pingpong(ctl = 0xFFFFFFC0A791A318, use_lock = FALSE) -018|mdss_mdp_display_commit(ctl = 0xFFFFFFC0A791A318, ?, commit_cb = 0xFFFFFFC002BDFD38) -019|mdss_mdp_overlay_kickoff(mfd = 0xFFFFFFC0A7B08360, ?) -020|__mdss_fb_perform_commit(inline) -020|__mdss_fb_display_thread(data = 0xFFFFFFC0A7B08360) -021|kthread(_create = 0xFFFFFFC05ABCE200) -022|ret_from_fork(asm) ---|end of frame |
勾选Local和Caller两个选项如下:

双链表的结构有前驱next指针和后继prev指针,所以prev->next == next && next->prev == prev这个条件是必现要成立的,我们来看这里的情况:
| -012|__list_add( | new = 0xFFFFFFC002BDF990 -> ( | next = 0xFFFFFFC002BDF9C0, | prev = 0xFFFFFFC00010356C), | prev = 0xFFFFFFC001B77DA8 -> ( | next = 0xFFFFFFC0ABA4C628, //prev->next显然不等于下面的next | prev = 0xFFFFFFC0ABA4C628), | next = 0xFFFFFFC0AB1D4178 -> ( | next = 0xFFFFFFC001B77DA8, | prev = 0xFFFFFFC001B77DA8)) //next->prev和prev倒是相等的 |
由上面传入__list_add的参数可知,prev == next->prev,但是prev->next != next,所以导致了上面的BUG_ON(1)异常!所以出问题的就是这个prev参数上,下面我们就来看看这个prev参数具体是什么内容?
注意到调用栈,__liast_add是从__internal_add_timer中调用过去的
| -012|__list_add(new = 0xFFFFFFC002BDF990, prev = 0xFFFFFFC001B77DA8, next = 0xFFFFFFC0AB1D4178) -013|__internal_add_timer(?, ?) |
下面我们来看看__internal_add_timer中的实现
| static void __internal_add_timer(struct tvec_base *base, struct timer_list *timer) { ... list_add_tail(&timer->entry, vec); } |
其中list_add_tail是inline的,所有调用栈上直接从__internal_add_timer调用到__list_add
| static inline void list_add_tail(struct list_head *new, struct list_head *head) { __list_add(new, head->prev, head); } |
由上面的分析可知,我们怀疑存在问题的prev实际上就是timer_list->entry->prev,并且我们也已经知道了这个存在问题的prev的值为0xFFFFFFC001B77DA8
| struct timer_list { /* * All fields that change during normal runtime grouped to the * same cacheline */ struct list_head entry; //entry成员是该数据结构中的第一个成员 unsigned long expires; struct tvec_base *base; void (*function)(unsigned long); unsigned long data; ... }; |
注意到:entry成员是该数据结构中的第一个成员,所以entry的地址就是这个struct timer_list实体的地址,也就是说这个timer_list类型的变量的起始地址也是0xFFFFFFC001B77DA8
下面我们就来看一下这个timer_list到底长啥样,调出view -> Watch窗口如下:
| (struct timer_list *)0xFFFFFFC001B77DA8 = 0xFFFFFFC001B77DA8 -> ( entry = (next = 0xFFFFFFC0ABA4C628, prev = 0xFFFFFFC0ABA4C628), expires = 4294963038, base = 0xFFFFFFC0ABA4C000, function = 0xFFFFFFC00077D4A8, data = 0, slack = -1, start_pid = -1, start_site = 0x0, start_comm = (0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0)) |
到现在为止,我们已经找到了timer_list实体的地址为0xFFFFFFC001B77DA8,回调函数的地址为0xFFFFFFC00077D4A8,下面我们就需要根据这两个地址找到这个timer_list实体在代码中到底是对应哪一个变量,他的回调函数又是啥?使用本文前面介绍的方法,很容易定位出来
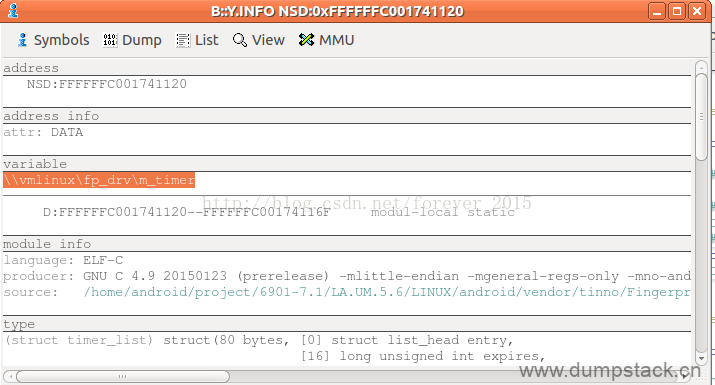
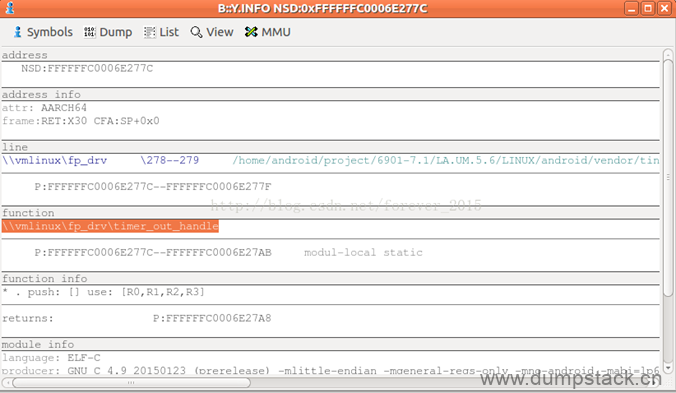
0xFFFFFFC00077D4A8位置对应的是定时器的超时函数,如下
| address NSD:FFFFFFC00077D4A8 address_info attr: AARCH64 frame:RET:X30 CFA:SP+0x0 line \\vmlinux\fp_drv \277--278 /home/android/work/prj/6901-7.1/LA.UM.5.6/LINUX/android/vendor/ti ------------------------------------------------------------------------------------ P:FFFFFFC00077D4A8--FFFFFFC00077D4AB function \\vmlinux\fp_drv\timer_out_handle ... |
如此,很清晰的显示了出问题的源码位置,到这里,异常定位分析就已经基本完成了,完成了追根溯源,剩下的就是去分析代码出解决方案了。
注意:下面两张图中的变量和函数对应的地址和上面示例不一样,放上来只是为了让大家看一下界面
未完待续。。。

文章评论
赞👍
你是我的光
请问T32工具安装包怎么获取?如何安装?
@王 官网注册账号就能下载
https://repo.lauterbach.com/infotext.html?message=release&id=t32release&link=0111198698292184621
@tmmdh 官网注册账号需要License Serial Numbers,这个在哪里获取呢